
For the past three months, half of us at Mux have been obsessed with HQ Trivia, while the other half silently regretted their Android purchases. When that HQ push notification hits at 12, the iPhones start coming out, and we rush over to a desk where I am projecting the HQ app onto a wide-screen display.
As questions appear on screen, a model runs and outputs scores next to each answer. (Disclaimer to our investors: This was mostly a nights and weekend passion project. Rest assured, Mux has not pivoted into the online trivia business.)
The accuracy of our model is currently hovering around 80-90%, which means it usually gets between 9 to 11 questions correct. This might sound high, but it still doesn’t translate into very many wins (which I will explain why later on).
Before I explain our methodology, let me address one important question:
Is this cheating?
Yes.
That might make you feel upset, and understandably so. But here’s something that might make you feel a little better—it doesn’t work very well. I detail our actual results at the end of this post, but rest assured, we are not making many trivia dollars from this model. It has helped us win some games, but most of the time we still lose.
While using machine learning does help us gain an edge, the time investment required was not worth the monetary reward. So why do we do it? Because:
- At Mux, we are passionate about all things video.
- Simple Question Answering is an interesting and hard to solve data science problem.
- I am ridiculously obsessed with trivia.
Trying to create a model that can predict the right answer within 5-7 seconds was a challenging and fun exercise. HQ also began making questions harder to Google, which forced us to constantly adapt our model. This type of adversarial machine learning is difficult to solve, and helped us test and improve our data science skill set.
How it works
The methodology we use is fairly straightforward:
- Run the image through an OCR (we use tesseract, although with some modifications)
- Parse the question and answers and run several different Google search queries. Scrape all the text from the search results.
- Get feature values (e.g. # of times an answer appears) from the text and pass into an XGBoost model.
- The model ranks the answers and outputs corresponding scores.
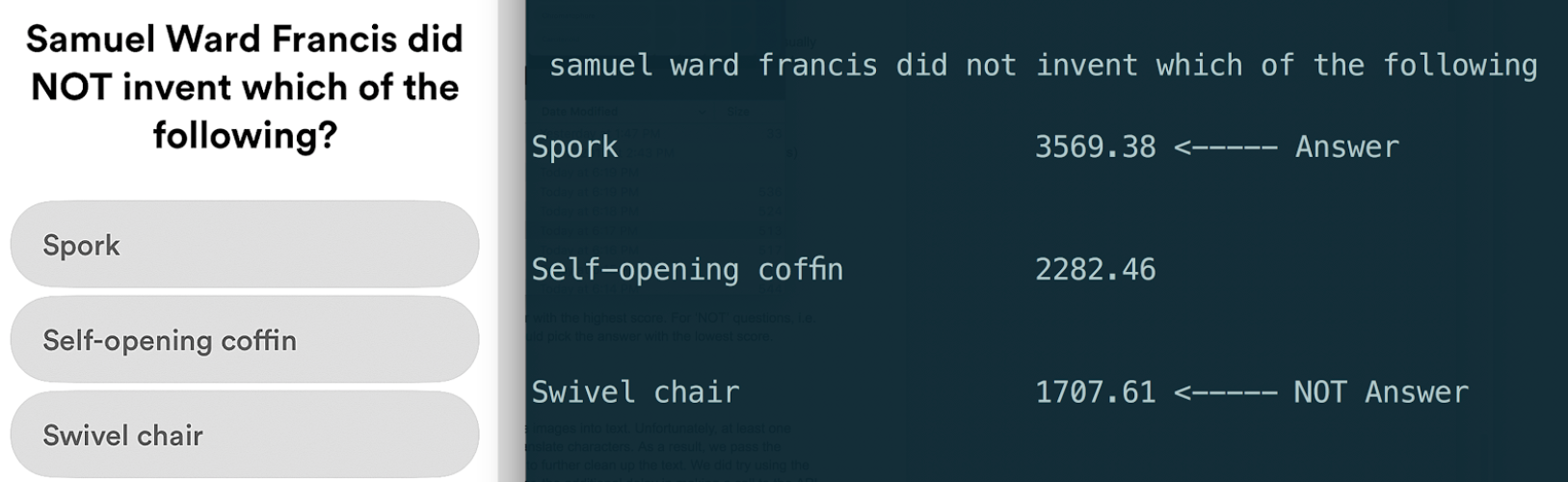
- For most questions, you pick the answer with the highest score. For ‘NOT’ questions, i.e. “Which of these is NOT…”, you would pick the answer with the lowest score.
OCR and Parsing
We currently use Tesseract 3.05 to translate the images into text. Unfortunately, at least one question per game, Tesseract will incorrectly translate characters. As a result, we pass the tesseract translation through a set of heuristics to further clean up the text. We did try using the Google Vision API instead of Tesseract; however, the additional delay in making a call to the API was not worth the increased accuracy.
Get Feature Values
Good feature creation is often the most challenging part of creating a high-performing machine learning model. We started off with some obvious features, such as the number of results on the page and the counts of answers in the search results. However, these aren’t perfect predictors and often failed for closely related or multi-word answers.
Search result numbers can also be unreliable because well-known answers will show up with many results regardless of whether it’s related to the question. Therefore, we tested several additional features, some of which performed extremely well. For example, we added a feature that measured the length of the answer and scored individual words within each answer. This added a “complexity” measure that helped expand the search space within the text.
For another feature, we scrape the text from question and answer search results and then used Facebook’s Starspace to create Doc2Vec embeddings. By measuring the cosine similarity between embedding vectors, we can see which answers are most closely related the question and to each other. This approach generalises well and is excellent for solving those tricky “Which of these is NOT…” questions.
Unfortunately, this feature was dropped from the model because Starspace took too long to run and couldn’t return vectors in time. Still, this inspired a modified approach of measuring answer covariance, which boosted the accuracy of the model by around 10% (i.e. one more correct answer per game!). These additional features allow us to get questions that would otherwise be impossible to Google.
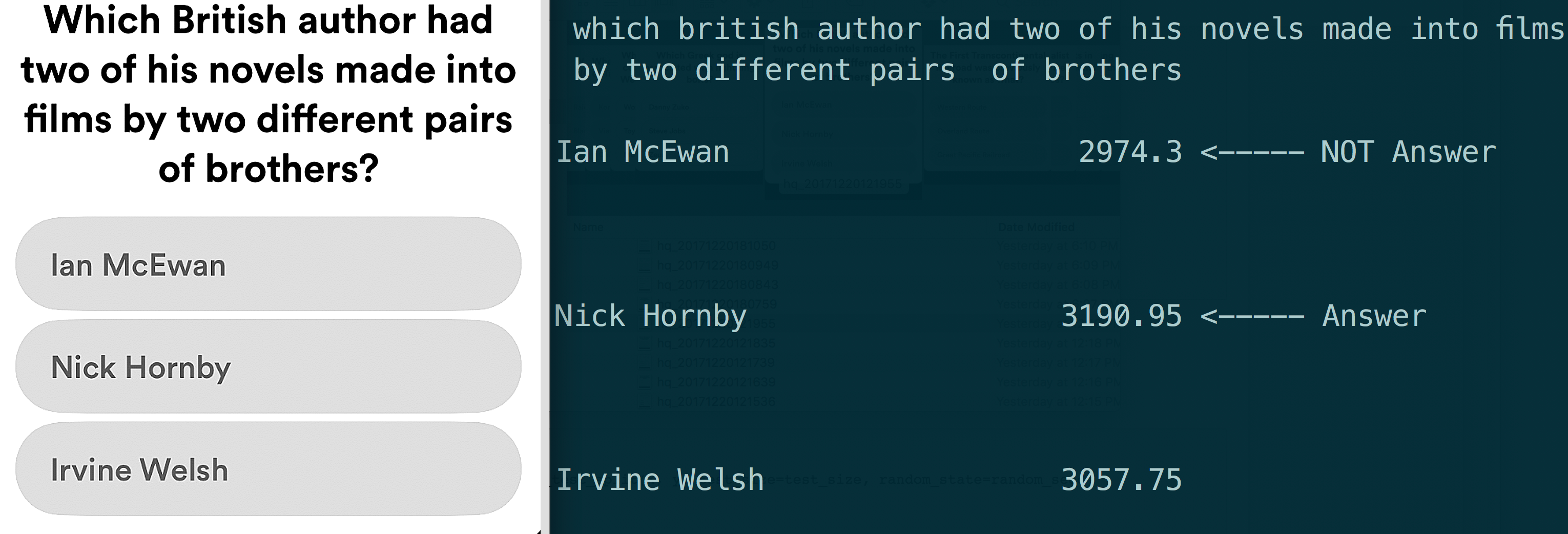
The quesiton above is a hard question to even manually search for because no relevant links appear, but the model still identifies the correct answer within a few seconds.
Run XGBoost model
For each game, we store a screenshot of the question into a database. Over the past few months, our database has grown to hundreds of questions, which is enough to create a training dataset for an XGBoost model. We chose XGBoost because of its high performance with nonlinear data and ease of implementation. Multivariate regression also works well, since most of the features are fairly linear, but with the number of features we have, it also tends to overfit.
I won’t go into the specifics of XGBoost models, but they are awesome. Their flexibility makes it easy to quickly define features and test them in the model without a lot of data munging. Since our dataset is still relatively sparse, we did a randomized cross-validation to tune the hyperparameters of the model.
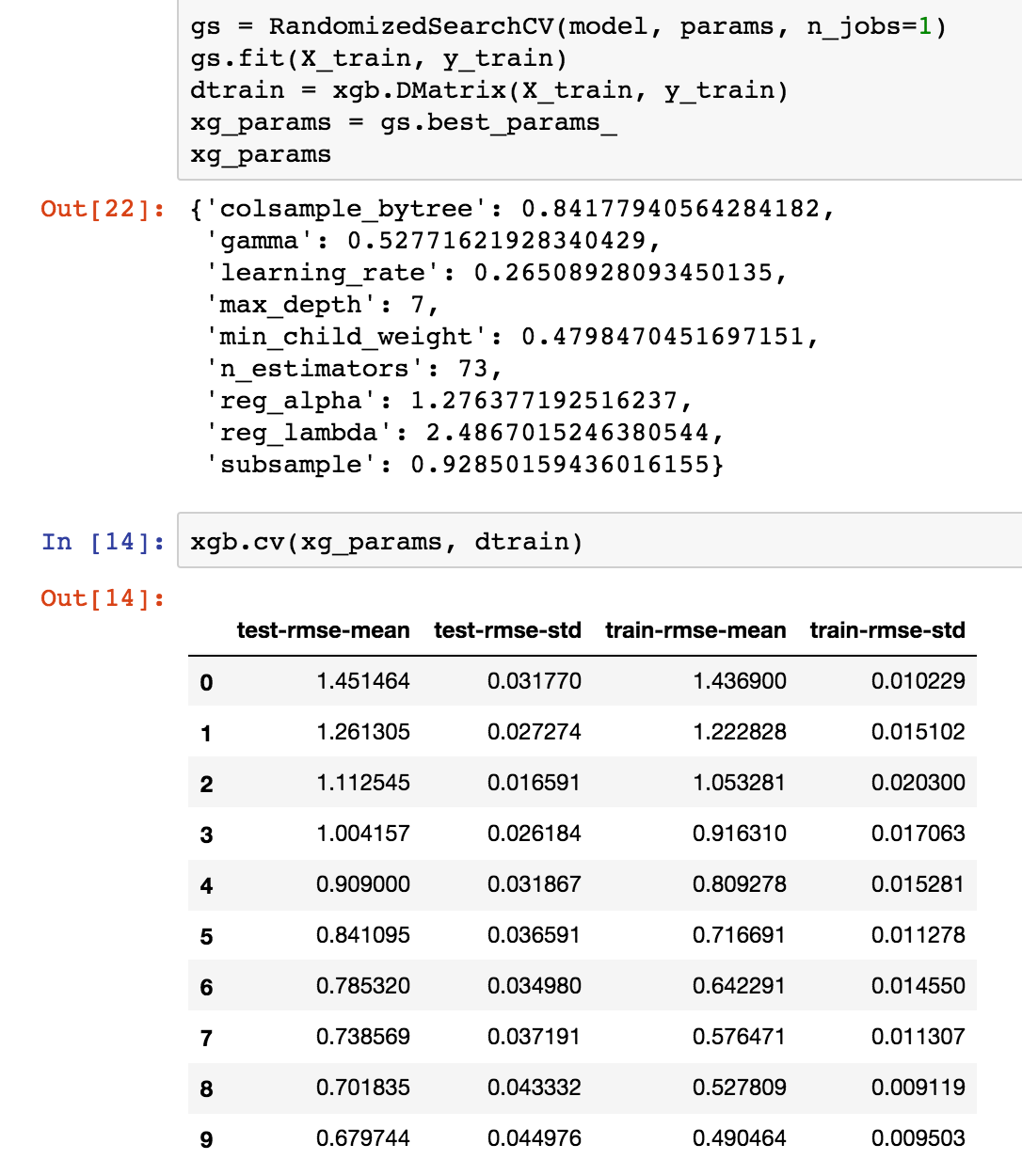
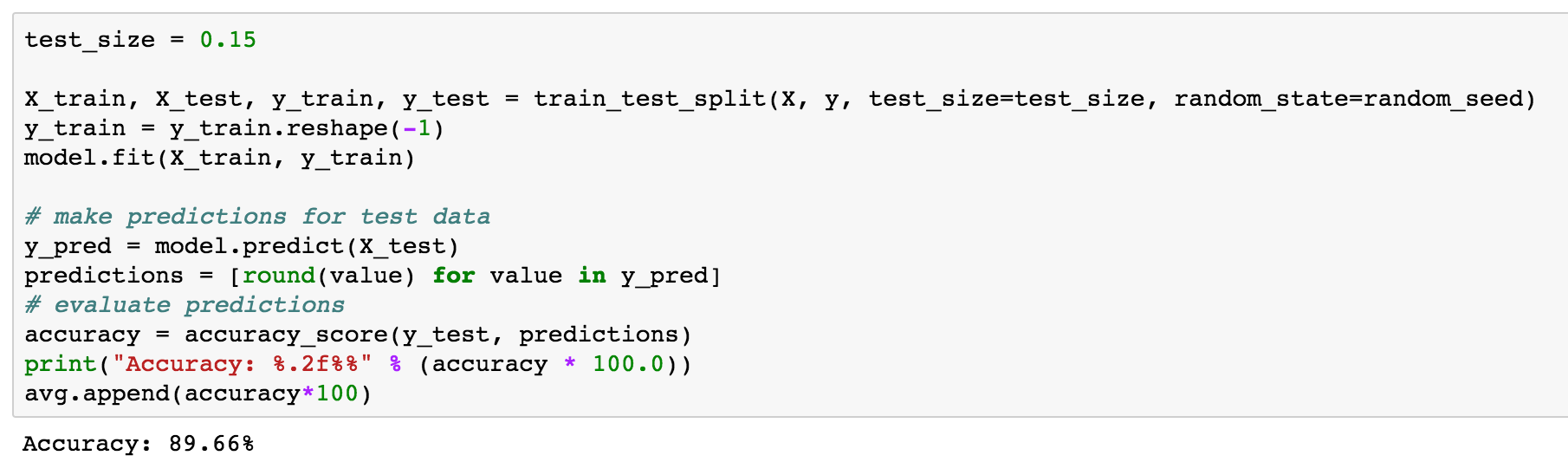
Since our question database will grow over time, our model should continue to get more accurate as we retrain it on new data. On some older test sets, we’ve been able to hit 89.7% accuracy, although on newer games we’re hovering around 80%.
Why we lose (and will keep losing…)
Despite having an answer key for most of the questions, our team hardly ever wins. Getting 12/12 questions correct is the holy grail here, but I doubt we will reach that level of accuracy on a regular basis. It might seem strange for us to consistently lose games where the model correctly predicts 11/12 questions. Shouldn’t we at least be winning those games 33% of the time?
I wish.
Unfortunately, we don’t know WHEN the model is going to be wrong, and so if the model is wrong just once, everyone is wrong together. Some questions are also truly unsearchable, because they require multiple pieces of data that has to be combined in unconventional ways (e.g. what pair of singers combined have the same total of Grammy wins as Beyoncé?). Luckily, these are generally awful and un-fun trivia questions for people to answer, so they do not show up often.
Still, the model has definitely improved our chances. In the past two weeks, our team has won four times, and I regularly make it past question 10. Needless to say though, the engineering hours that went into creating this model has not resulted in a positive ROI. (However, it’s worth noting some of the techniques we tested in our model did inspire ideas for other data science projects in our video product, such as using an autoencoder for detecting image content.)
Can machine learning really work for trivia?
Several blog posts have come out claiming they’ve “hacked” HQ, but I can say with certainty that none of them are consistently winning games. We’ve tested our model, which uses more features and data than any other approach I’ve seen, on hundreds of questions. With 80% accuracy, you can expect to win 7% of all games, which is around where our model stands. Using more rudimentary googling and webscrapes, the accuracy is at most 65%. That means you only have a half-percent chance to win any given game.
So rest assured, hackers are not ruining HQ. Last month, only a single winner won the $1500 prize, and payouts have remained fairly consistent over time.
To date, we have made $76.13 from playing games with our model.
At the end of the year, Mux will make a charitable contribution equivalent to our total winnings. This was never about the money; it was about the challenge.
Thanks for reading and watch for an upcoming blogpost where we take a deeper look into how HQ publishes video.


