
One of our aims at Mux is to make it easy for every developer to create great video experiences in their apps. To help you build new apps, we're building more SDKs for a wider variety of languages this year.
We finished 2018 with two SDKs, mux-node-sdk and mux-elixir. By the end of 2019, we aim to have SDKs available for over 10 languages. We're still finalizing which languages we're going to deliver, and in which order, so if you have a burning desire for a Mux SDK in a particular language, please let us know!
Traditionally, building SDKs by hand can be a slow and painstaking process, with the need to manually develop a lot of code in languages which may not be your specialism. For a few years however, there has been an increase in the number of companies using code generation to create their SDKs for a variety of languages. We decided that, as a small company, this approach was the best way for us to deliver and maintain great SDKs while still focusing our team building a great product.
While large corporations including Google and Amazon Web Services have been generating their SDKs for years, they’ve been using closed-source toolchains, oriented around internal-only API description files. Over the last few years however there have been several projects aimed at standardising REST API definitions and interchange formats, we’ve been following along with projects like Swagger and API Blueprint for some time, and feel they offer active communities which we can be a part of, and powerful toolchains which we can utilise.
OpenAPI V3
In July 2017, the first version of the OpenAPI V3 specification was released. OpenAPI is a standard for describing RESTful HTTP APIs which grew out of the older Swagger Specification, after its was donated to the OpenAPI Initiative following SmartBear's acquisition of Reverb Technologies.
OpenAPI is a way of describing your APIs in a YAML (or JSON) file. You model the data structures exposed and accepted by your API, and tie them to the HTTP calls that a client can make to your services. We found that a great way to get started with OpenAPI is to understand and experiment with the simple Petstore example which is part of the OpenAPI specification. If you prefer a tutorial rather than experimenting, then you may want to start here.
We spent time looking into the tooling surrounding the OpenAPI ecosystem to understand if it met our needs, which it seemed to comfortably. One of the biggest new features in OpenAPI V3 is support for Polymorphism in API endpoints, which is something which we make use of within the Mux API. (For example on the Create Asset API call
The community surrounding Open API V3 has been growing since the release of the latest version of the specification, and support is becoming more comprehensive across OpenAPI toolchains. However as we started utilizing a lot of the tooling, gaps started to appear.
OpenAPI V3 Tooling
While investigating the feasibility of generating our SDKs, we spent time looking into the tooling that we'd have at our disposal - here's the ones we found that seem to work well, and what we used them for.
swagger-cli
swagger-cli is one of the main tools you need to get used to using as part of your toolchain. As is obvious by the name, swagger-cli is a tool which pre-dates the OpenAPI specification, but has been updated to be compatible with OpenAPI V3.
We found ourselves using the two operations swagger-cli provides frequently while we were working with OpenAPI:
swagger-cli validate
swagger-cli bundle validate is used to validate the contents of an OpenAPI YAML file performing some checks against the OpenAPI specification. This seems fine, but as I’ll talk about later, this is not a comprehensive validation.
bundle* is used to combine together a set of OpenAPI YAML files which are linked by $ref parameters into a single JSON file. $ref parameters are great because they allow you to use composition in your data models, as well as letting you break down your API descriptions into multiple files for a more maintainable codebase. It’s useful to combine your definitions together when you want to distribute a single file defining your APIs, or for use in other tools which don’t fully support the OpenAPI specification.
* Note that running bundle does not run validate first Our opinion is that it probably should, and then decline to bundle if the validate fails. We raised a Github issue to get feedback, but it seems the consensus is that the current behaviour is desired.
ReDoc
One of our long term goals for documenting our APIs via OpenAPI is that we also want our documentation to be generated from those definitions. We experimented with using ReDoc to do just that. ReDoc can generate a static site, or even serve a simple web server which produces a powerful standalone docs site.
We found using Examples in our OpenAPI definitions was also very helpful as they appear in the generated ReDoc site. This is really great as you start to build out your API descriptions as it allows you to better visualize what your APIs will look like to clients.
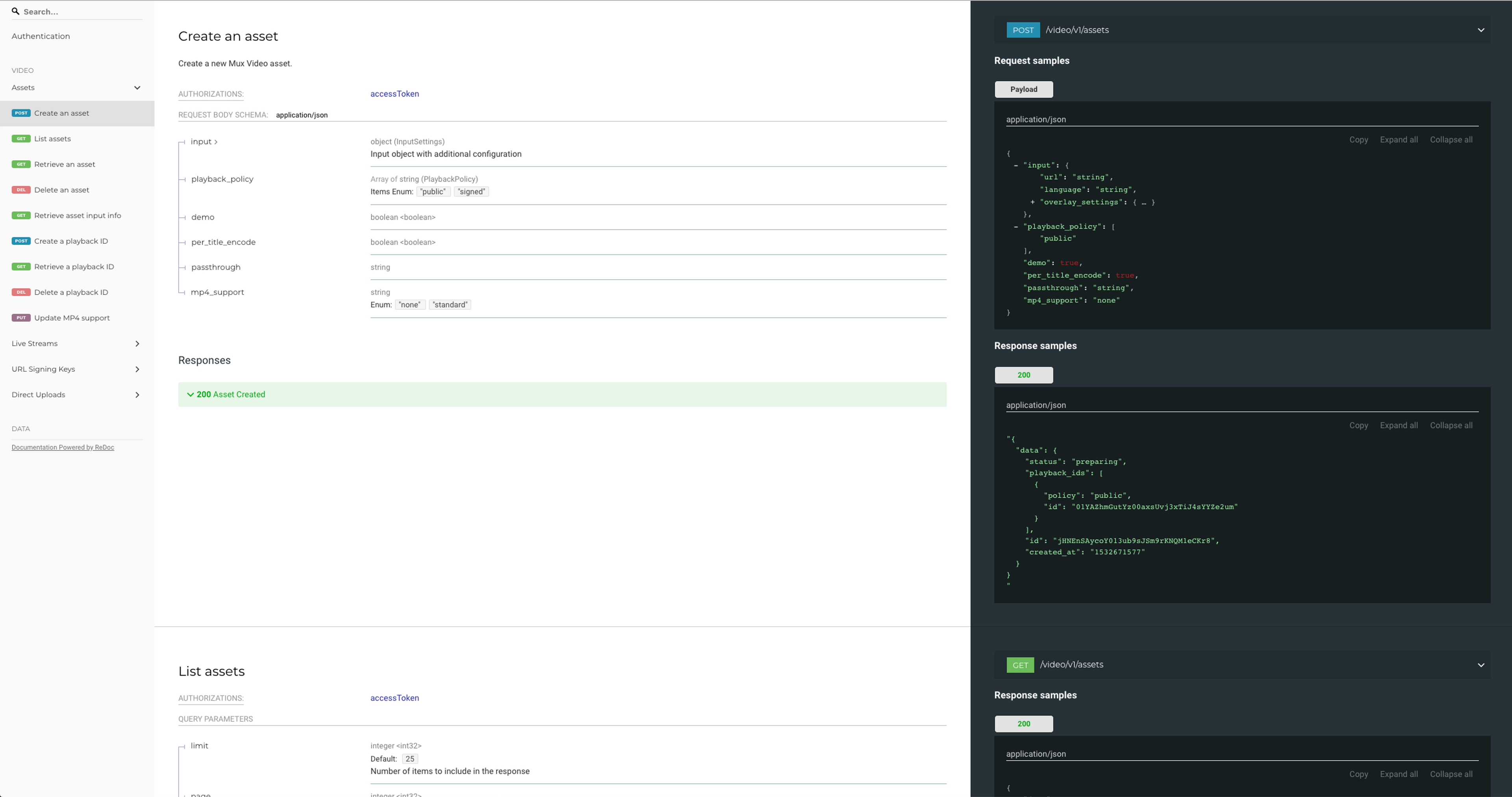
ReDoc displaying the Mux Asset API
Our current docs site isn’t going anywhere so don’t worry, but we’re hoping to get the auto-generated docs up later this year.
OpenAPI Generator
OpenAPI Generator is a comprehensive Java application which can generate client and server side code from your OpenAPI models. It’s a large code base with support for generating client-side SDKs in over 20 languages as well as nearly the same number of server-side implementations. This is the tool we’ve been working with to generate our new SDKs.
While OpenAPI Generator is very comprehensive, we did find a few rough edges when trying to use it ourselves; documentation can be inconsistent and the error messaging difficult to follow. This coupled with being a large Java code base (around 20,000 lines) with liberal usage of abstract classes and inheritance means that debugging why something isn’t working the way you’d expect (or an occasional null pointer) can be incredibly challenging.
There’s two main components to how OpenAPI Generator generates source code:
Mustache Templates
The core of OpenAPI Generator is based on Mustache templates. Every line of code in your generated SDK is created by reading a template file in and substituting values into it based on your OpenAPI descriptions.
This is a really simple approach, but also adds great flexibility for customization. OpenAPI Generator provides tooling which allows you to extract the templates embedded in its JAR file into a directory, and then use the template files from that directory when generating code, providing simple customization without the need for recompiling the Java application. For example, here’s the templates used when generating a Python SDK.
Generator Classes
Each language (or framework) you can generate has a java class which defines the behavior for generating code. This class is responsible for deciding what template files to load and generate based on your OpenAPI definitions.
We found it very helpful to familiarize ourselves with the inner workings of each of the generator classes that we wanted to work with. Here’s the Java class which generates a Python client SDK. Much of the business logic which defines the behaviour of the code generation is embedded in this Java. The drawback of this approach is that if want modify the business logic for code generation, you can’t just change the Mustache templates, you’ll have maintain your own fork of the OpenAPI Generator code base.
Mermade openapi-codegen
We wanted to mention Mermade’s openapi-codegen
project too. Fundamentally it performs the same behaviors as OpenAPI Generator, but it’s a simpler, much more minimal implementation written in Node.js. We quite like this project, but it’s a distance behind OpenAPI Generator at the moment. It actually uses the same Mustache templates which are used in OpenAPI Generator, but with the behaviors for each language and framework written in JavaScript.
While the re-use of templates is great, it does mean that the templates embedded in this tool often fall out of sync with the versions in OpenAPI Generator, so you may find issues in templates which have already been fixed elsewhere.
We’ll be following along closely with this project to see how it develops in the hope that it provides us a simpler, more lightweight toolchain in the future.
Challenges we encountered
For the last couple of months between other projects, we’ve been working on code-generating some SDKs using the tools we described above. Unfortunately it wasn’t all smooth sailing, but we’re documenting what we learned here so that hopefully other people can learn from our headaches!
Tooling support for OpenAPI V3 is very inconsistent
OpenAPI V3 has been out for a while now, with the specification being finalized over 18 months ago. Unfortunately this doesn’t appear to mean that tooling has caught up to the specification completely. Every tool we worked with had a different level of support for the specification: some were very strict about their interpretation, while others were incredibly lax. We couldn’t find a single tool which was able to correctly validate our OpenAPI definitions, so we had to rely on multiple while also building our own validator.
ReDoc is an interesting example - it is incredibly relaxed about its validation of the specification, and works in many cases when we have files that are a long way outside of the specification. This served as a painful lesson because we started by developing against ReDoc, which lured us into a false sense of security that the files we were writing would work well in other tooling.
OpenAPI Generator’s support for OpenAPI V3 was also a hurdle to overcome: it doesn’t play nice with YAML definitions that make use of $ref. As we mentioned before, $ref is a great way to break down your OpenAPI definitions, but if you want to be able to use these definitions with OpenAPI Generator, you’ll need to use swagger-cli combine to create one, combined JSON file with all your references embedded. You can then point OpenAPI Generator at this JSON file and code generation should mostly work as expected.
During our work, we also switched to OpenAPI Generator 4 to test some experimental features, only to discover that all of our OpenAPI files were no-longer valid. Upon investigation we discovered that OpenAPI Generator 4 was using an updated version of swagger-parser, which unfortunately introduced an issue where any OpenAPI files using $ref parameters in paths would no-longer pass validation. The issue has since been resolved on swagger-parser’s issue tracker, and is currently awaiting a dependency update in OpenAPI Generator. Unfortunately this meant disabling validation to be able to continue our experiments with OpenAPI Generator 4.
Support for Polymorphism in OpenAPI Generator isn’t consistent
In the Mux Video API, we use polymorphism to allow APIs to behave differently depending on the structure of the API request you make. This is to make it as simple as possible for you to work with our APIs. For example when you ingest an asset, you have 3 different request bodies you could make to the POST /video/v1/assets endpoint:
- Where input is a simple string.
- Where input is an input_settings struct.
- Where input is a list of input_settings structs.
One of the highly touted features of OpenAPI V3 was support for this type of polymorphism via the oneOf or anyOf features. Unfortunately OpenAPI Generator V3 did not yet support these features. When OpenAPI Generator 4 betas were announced, we spotted in the release notes that there was support for polymorphism.
With great excitement we switched out our Generator for the V4 (causing our API definitions to fail all validation - see above…), and re-generated our SDKs. Unfortunately what we discovered was that this support had only been added to the core of OpenAPI Generator, and was not yet supported in the vast majority of the languages and frameworks that OpenAPI Generator can output.
Until we have full polymorphism support in the languages we’re generating, we made the decision that we would expose the more comprehensive version of each API call to make sure that you’re still able to access every feature we offer in Mux.
OpenAPI Generator falls back to Inline types a lot, and this is bad…
In a past life I used to write a lot of perl. One of my favorite CPAN modules is common::sense - it does many things to encourage you to write good perl, but one of the best things it does is force all Warnings to be Fatal. In my opinion, OpenAPI Generator needs to start doing the same thing.
As we’ve already discussed, validating of OpenAPI 3 files is inconsistent across tooling. We often ended up in the situation where we’d be writing what we thought were valid API definitions, which passed all the validation we had, but would cause warnings in OpenAPI Generator. In particular, the warning that we saw a lot of as we were learning the ropes was:
[main] WARN o.o.codegen.utils.ModelUtils - #/some/reference/here is not definedIt’s an easy warning to ignore, especially given that OpenAPI Generator is pretty chatty as it generates code. When you see this warning, you’ve probably failed to define or alias one of the models which you’re using in your APIs in your schemas/components. This is a violation of the specification, but is a great example of a case where none of the validation tools which exist today will catch your mistakes. ReDoc will happily generate you documentation with these missing references, and swagger-cli validate thinks everything is just dapper.
The real problem comes when you look at the code which you’ve just managed to generate. If you look further down your logs from your generation, you’ll probably see more log lines like this:
[main] INFO o.o.codegen.AbstractGenerator - writing file /some/path/here/mux_python/models/inline_response201.py
[main] INFO o.o.codegen.AbstractGenerator - writing file /some/path/here/mux-python/test/test_inline_response201.py
[main] INFO o.o.codegen.AbstractGenerator - writing file /some/path/here/mux-python/docs/InlineResponse201.mdWhat’s happened here is OpenAPI generator can’t find a definition for your type, so its had to generate you an inline type for the API call in question. You could use this generated code, but it would make your SDK impenetrable to developers. In our mind we think this should be a fatal error - there’s no way anyone would want to use the code which is generated.
In order to combat these issues, we’ve done two things:
- In our custom validator, we’ve added type alias checking. We check that every object schema, every API request/response schema, and parameter schema we use is correctly aliased in the components/schemas section of our API definitions.
- We check the output of OpenAPI Generator in our wrapper shell script, making sure that the word “Inline” doesn’t appear anywhere.
We’d strongly encourage you to check the same things if you want to use OpenAPI Generator. We’re also planning on open-sourcing our validation tools soon, so if you’re interested, be sure to keep an eye on the Mux Blog for announcements.
$refs are great, but inherently limited
As we’ve mentioned before, you can use $ref to modularize your OpenAPI definitions. This is great, but one of the major changes between Swagger V2, and OpenAPI V3 is that $ref can no-longer be used everywhere.
From the OpenAPI documentation:
A common misconception is that $ref is allowed anywhere in an OpenAPI specification file. Actually $ref is only allowed in places where the OpenAPI 3.0 Specification explicitly states that the value may be a reference. For example, $ref cannot be used in the info section and directly under paths
While it makes sense to limit the places $ref can be used, there’s two problems that arise from the limitations that have been put in place:
- There’s no definitive list of where $ref can be used in the OpenAPI V3 specification or on the documentation website. This makes the barrier to entry for OpenAPI much higher, and encourages developers not to modularize their definitions because they don’t understand where you can use $ref and where you can’t. We appreciate that reading the the specification is important, but we’re talking about a 93 page, 15,000 word document…
- The places where you can use $ref don’t make logical sense for large APIs. My favorite example is the one referenced in the OpenAPI documentation - you can’t use a $ref directly under paths in your index.yaml. This seems inconsequential, but in practice means that your index.yaml will always be very large, since it has to include every HTTP API call a user could make to your service. Ideally we’d just $ref a single file for each of the HTTP endpoints Mux has (around 5 of them), but instead we have to map every API call, which works out as over 40 lines of code, for just the /video APIs.
Generated SDKs are going to closely match you API Structure
If you look closely at the Mux /video API, you’ll notice that we follow a consistent pattern with our API structure, both in terms of our path layout, but also our response format.
At the HTTP level, every successful request you make will return a JSON response where the objects you want to work with will be returned in a key called data. This is to help our API be more flexible as we grow. We want to be able to return extra metadata about the API calls you make without having to change the fundamental return type, or resorting to passing around actionable information in HTTP headers. These concepts are borrowed from standards like JSON:API, which among other things, lets you embed objects which are referenced in data in other fields.
With OpenAPI we wanted to authentically match our API layout with our definitions. Unfortunately doing this has knock on effects to the way you interact with the generated code.
As we’ve already mentioned, for every API request/response you define in OpenAPI, you need to define a schema if you want OpenAPI Generator to not generate Inline’d code. In the Mux case however this means that we have to also have wrapper objects for each of our API response types.
Let’s look at an example. We have an API for listing the Assets in your Mux environment. To model this we need the following:
- A model for an Asset
- A model for ListAssetsResponse
The OpenAPI definitions look something like this:
And we’d map this onto our HTTP API as follows:
This seems fine in principle, but as we said earlier, it means that your SDKs will mirror this layout. This means:
- You’ll end up with a type called ListAssetsResponse
- With one field data
- Which contains the API response you’re actually looking for
When we generate Python code for example, a call to the List Assets API ends up looking something like this:
This doesn’t look bad when you know what you’re looking for, but it will almost certainly trip up new developers when they look at our generated SDKs.
We thought a lot about how we could manipulate OpenAPI Generator’s output to hide the data element from our users. The easiest way would be to simply model our APIs in OpenAPI without including the data field, and then add a middleware in the generated rest code which unwrapped the response. We ultimately decided not to go down this route for 2 reasons:
- We want to invest in our OpenAPI toolchain. This means potentially using OpenAPI end-to-end for creating our server-side stubs and models as well as our SDKs and documentation. If we don’t represent our HTTP API accurately in our OpenAPI, we can’t do this.
- We want to gauge if this is an actual issue or not - if we see a lot of feedback or issues from people using the SDK saying they had issues, we’ll revisit this decision.
- We believe good documentation and examples can help the getting-started experience, so we’re focusing on making it clear that these SDKs are representing our APIs accurately wherever possible.
There’s no consistent way to break down and structure your OpenAPI definitions
We’ve talked a lot about utilizing $ref to break up our OpenAPI definitions and to reference common objects. What we haven’t talked about is the layout of those files. A lot was written about good ways to break down your Swagger definitions into a more sensible directory structure, but not much has been written about doing the same with OpenAPI.
The big challenge here is that (as we’ve talked about before), we can only use $ref in a limited number of places in our OpenAPI definitions (Swagger was much more liberal). We experimented with a few ways to layout our OpenAPI YAML repository, and here’s what we came up with:
(If we’ve missed some best practices here, please let us know)
index.yaml contains our main OpenAPI definitions. It’s a standard OpenAPI definition, containing the usual things you’d expect, including paths and components. We alias all our models from components/schemas to a files deeper in the directory structure.
Video/api/v1/ contains a file for each top level API endpoint we have, eg /assets or /live-streams - we enforce the naming scheme of each of these files within our validator.
When we reference an API from our paths in our index.yaml, we reference an an API call in those files, so our paths looks something like this:
We’d love to clean this up and just $ref a single file for each API endpoint, but this isn’t possible as per the limitations on $ref usage in the OpenAPI specification.
Our schemas directory contains two collections of schemas:
- At the root of the directory, we have the schemas for our fundamental types - eg: Asset, LiveStream
- In /api/v1/, we have our schemas for our API request/response patterns. You’ll notice that we also have slightly more generic versions of these, for example AssetResponse, which is a type we use for any API response which contains an Asset wrapped in a data field.
- The validation script we wrote tries hard to enforce this directory structure, and also checks that every type in our schemas directory is aliased in our components/schemas section of index.yaml.
Our first OpenAPI generated SDK: mux-python
After all this work, we’re really excited to announce our first code generated SDK - mux-python. This simple API wrapper makes it really easy to work with Mux video from any Python app you write.
The code in mux-python is around 98% generated by the python client templates present in OpenAPI Generator V4. However, we did decide to extract the templates and source control them separately from the SDK we’ve published publicly on Github. There’s nothing majorly different about our templates, but here’s a couple of highlights of the changes we chose to make:
We wanted to add better exception handling than the default generated code. By default the code generated treats every non-2XX status code the same way, by throwing a generic exception. We wanted to give our users a better experience by throwing more specific exceptions based on the status code we receive from the Mux APIs.We’re hoping to push our changes back upstream to OpenAPI-generator, as we believe that it makes a lot of sense to handle a certain subset of status codes in more meaningful exceptions as default behavior. Specifically, we’re suggesting that the following status codes should be mapped to specific exceptions by default:
- 401 Unauthorised
- 403 Forbidden
- 404 Not Found
- 5XX Internal Server Error
We’ve got an open issue on with OpenAPI Generator for the python SDKs, and we’re looking for feedback on if this seems useful.
We wanted to fully customize the README.md file in our repositories so that we could offer users of our SDK a better experience when they landed on the Github repository for the first time. It also allowed us to provide better examples in our getting started documentation in the SDK.
We didn’t like the amount of commenting at the top of every file generated. We were much more comfortable with a shorter more concise comment explaining that this file was code-generated, and shouldn’t be edited - we also note this out in our README file.
Our Toolchain
Our toolchain ended up being less simple than we were aiming for, but is mostly composed of the open source tooling we described in our tools overview. Here’s a diagram showing the components and flow of data through our approach:
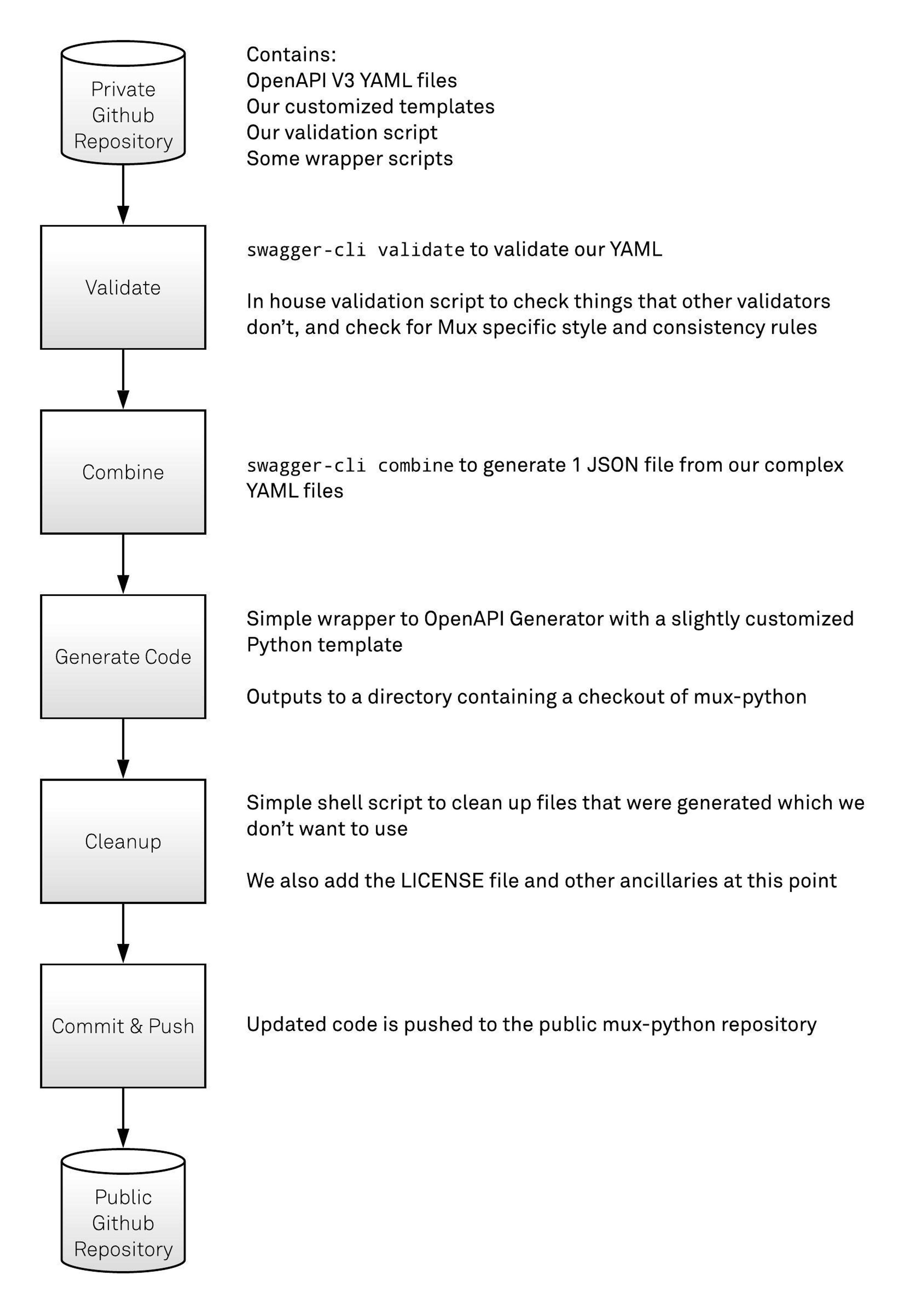
Mux’s OpenAPI code generation flow.
The Future
We’ve been really impressed by the speed at which we’ve been able to generate comprehensive SDKs for Mux using OpenAPI. We’re excited to continue to be part of the community and work to improve tooling, templates, and the ecosystem as a whole.
We’ve got quite a list of things we want to do with OpenAPI, here’s a small sneak preview of what we’re thinking thinking about right now:
- Publish our combined OpenAPI JSON definitions so that we’re not the only people able to generate SDKs
- Generate more SDKs (Tell us what languages we should be doing next!)
- Open source our own validator, and/or contribute more back to the community validators
- Try to come to a consensus with the community on best practices for repository layout
- Think more about our API to SDK/wrapper mapping for JSON:API style APIs
- Add more helper methods for things like signing URLs using keys you’ve ingested into Mux, just like we have in the Elixir and Node SDKs.
- Add support for Mux /data
- Improve our development workflow and start from OpenAPI definitions, and generate API stubs before building products
Summary
OpenAPI is a great standard for modeling your APIs, and the tooling to generate your SDKs from it works well across a variety of languages. However this is still an evolving space - you can’t expect everything to work perfectly the first time - you’ll have to invest in your toolchain, and work with the community to improve the tools that are out there.
The rewards are tangible though, the speed of the development of the SDKs we’ve been working on has been really impressive, we’re especially loving the elegance of having a simple toolchain to generate updated SDKs when adding new API calls to already existing products.
Keep an eye on the Mux Blog more SDK announcements soon, and remember to let us know what languages we should be working on next!


