
Mux receives a continuous stream of video-view event data, every second of every day. Some of these views indicate errors during the delivery or playback of video. How can we detect error spikes in real-time across a customer property or a particular video title?
In Summer 2016, Mux began work on a system for real-time anomaly-detection and alerting. Requirements included:
- Ability to support an unbounded number of customer properties and video titles (i.e. must scale easily without sacrificing performance)
- No reliance on database polling
- Ability to support alerting for infrequently-played video-titles (could take days to accumulate enough views to make an accurate determination)
- Low latency
- Fault tolerant, because things happen
This is the challenge we’ve taken on and achieved with the help of Apache Flink.
The Apache Flink project is a relative newcomer to the stream-processing space. Competing Open-Source platforms include Apache Spark, Apache Storm, and Twitter Heron. What sets Flink apart is its ability to handle unbounded event streams with guaranteed exactly-once event-time processing. Quite a mouthful! Let’s take a look at each of these qualities.
Unbounded Event Streams
Batch processing systems... phew, what a way to start off a paragraph. They’ve existed since the dawn of computing. Accumulate a finite amount of data, bounded by a window of time, number of records, or some other feature. Neat, simple, and straightforward. And high latency. And potentially inaccurate when performing calculations that span batches.
Flink is different. Flink can perform real-time Map-Reduce operations on streaming events. The Reduce operations can be viewed as batches in their own right, and can exist for a configurable length of time or number of events. Flink also allows for processing & event-time timers on in-flight windows (more on time-semantics later). One possible use for timers is to close windows that have been open for too long.
"In a stream-based design, [...] data records continuously flow from data sources to applications and between applications. There is no single database that holds the global state of the world. Rather, the single source of truth is in shared, ever-moving event streams" (Tzoumas & Friedman, "Introduction to Apache Flink")
Exactly-Once Processing
Flink has been cited as an example of Kappa Architecture, the logical successor to the Lambda Architecture. Lambda systems rely on a stream-processing engine like Apache Storm to make a first pass on the data, and then a batch-processing engine like Hadoop MapReduce to make a second pass performing exactly-once processing on the data. This implies two distinct systems with often radically different codebases working toward the same goal, but with different views of the data. No thanks.
"Duplication is the primary enemy of a well-designed system. It represents additional work, additional risk, and additional unnecessary complexity." (Robert C. Martin, "Clean Code")
Lambda Architectures must also store the raw event stream for some length of time to feed the batch system, which introduces non-trivial storage & memory requirements.
With Apache Flink it is possible to get exactly-once processing results with only a single pass, in real-time. Benefits include a simplified codebase (no need for separate real-time and batch systems) and no requirement to store the raw event stream.
Event-Time Processing
There are 3 modes for processing time-series data:
- Processing-Time: Using the system-time when an event is processed
- Event-Time: Using a timestamp from the event record itself
- Ingestion-Time: The time at which an event entered the processing pipeline, conceptually a mixture of Event-Time & Processing-Time (infrequently used)
Processing-Time is the easiest to implement, but has several drawbacks:
- Requires strict ordering of data
- Results are affected by the speed of processing
Event-Time processing is significantly more difficult to implement but is immune to the problems associated with Processing-Time. Fortunately Flink makes it trivial to process streaming data using Event-Time; upon reading an event record from a stream-source (e.g. Apache Kafka, AWS Kinesis), Flink invokes a user-defined method to extract Event-Time from the event record. The Event-Time will then be used with that record as it advances through the pipeline.
Data can also be received out-of-order and processed deterministically through the use of Event-Time watermarks. For example, a watermark of 2 minutes would permit up to 2 minutes of event-time for all events older than a given time to arrive. Once the watermark is finalized, all pending events are ordered according to their Event-Time timestamps and processed. This makes it possible to read & join multiple independent sources (i.e. Kafka or AWS Kinesis shards) without any loss of accuracy.
Lastly, Event-Time processing permits faster-than-real-time processing with no loss in accuracy. Suppose there’s a network outage that disrupts processing for several minutes. A system that relies on Event-Time will eventually resume and process events exactly as it would had there not been a disruption in service. The same applies to scheduled downtime, application upgrades, etc.
How Mux is Using Flink
Now that you're convinced of Flink's awesomeness, I’ll share how it is being used at Mux to drive real-time alerts.
Mux receives a constant stream of video-views events, some of which indicate errors during playback. Events associated with a video-view are sent to the Mux Event Ingestion service. Events for a given view are accumulated until the view finishes successfully or an error occurs. At this point the view details are sent to an AWS Kinesis stream. The Mux alerting application runs in an Apache Flink cluster and reads from the Kinesis stream. The Flink application performs a real-time MapReduce operation to calculate the playback error-rate across each video title within a customer property and across an entire property.
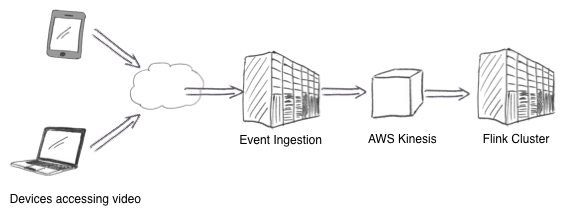
We’ve also used the Flink rolling-fold operator to accumulate error-rate observations over an extended period for a given customer property and error-type. This makes it possible to apply novel anomaly-detection algorithms that place current observations in the context of past observations. For instance, an error-rate of 5% might be wildly unusual for one customer, but totally normal for another. We can use this accumulated state to define “normal” in a variety of settings without relying on static thresholds.
What’s Next
Flink has been instrumental in building Mux's alerting capabilities and will continue to play a big role as the Mux product offering expands. We hope that you’ll consider Apache Flink for your own analytics needs and join the growing community of Flink users & developers. Keep following the Mux Blog for more posts related to Apache Flink and real-time analytics!


