
Mux Video makes it easy to build video-centric applications with global audiences that expect a seamless viewing experience regardless of device or location. In order to help accomplish this lofty goal we partner with Content Delivery Network (CDN) providers such as Fastly, Cloudflare, and Highwinds that specialize in caching data and distributing it across worldwide networks. Leveraging these services allows us to deliver video, thumbnails, subtitles, and other content more efficiently from our origin to reduce costs as well as improve the end-user experience. We pass on these savings to our customers so the better we are at this the more everyone wins.
By design, this model shifts a huge amount of traffic away from our origin and onto the CDN edge Points of Presence (POPs). Given the CDNs bill us based on the traffic that they serve on our behalf, this leads to an important question: since our origin clusters are no longer solely responsible for egress traffic, how do we monitor our video product's performance and invoice our customers correctly? Luckily most CDN providers make it possible to retrieve request level logs through either an API that can be polled or by streaming to an external source, granting us a level of visibility similar to our origin servers. In our case, all of our partners write log files to Google Cloud Storage (GCS) buckets over a configurable interval. These files contain logs for every single request served along with extra metadata such as the POP that served it, whether or not that request passed through to origin, and so on. We process each one of these log files and write their contents into a pipeline that drives not only billing but also dashboards with internal metrics like this one:
With respect to billing, invoicing customers based on usage means that it's extremely important to ensure we're processing every single log once and only once to avoid over or under charging our customers. There are several distinct systems in this pipeline and the data they emit needs to be consistent with this guarantee, which is more formally referred to as Exactly-Once Semantics (EOS). We use Apache Kafka to stream data between these components and Apache Flink to process most of that data, which has excellent EOS support that is simple to configure. Unfortunately, this strategy is difficult to apply when it comes to getting these logs into the pipeline in the first place; that is, ingesting from a remote source that we do not control (i.e., GCS) into our own system.
Our solution to this has been to run a Golang service we’ll call the “Logpuller” that's responsible for downloading, parsing, and writing each individual log to Kafka for the rest of the nodes in this pipeline to work on. This service had been operating relatively untouched for years but unsurprisingly the explosive growth of Mux Video quickly outstripped the limits of this system. The way it generally worked was to list the remote directory and then sequentially download and process each file, which meant that the file retrieval and processing logic was tightly coupled. Arguably the most glaring shortcoming in this design is the fact that it isn’t safe to run multiple concurrent instances of the Logpuller for the same CDN. Without a way to coordinate which files were getting processed, running multiple instances meant duplicating all of the work. The only way to increase throughput was to allocate an absurd number of resources to the single instance and hope it could keep up. It became a relatively regular occurrence for on-calls to get paged about high resource utilization and frantically vertically scale up the instance, culminating in our eventually leaving the service heavily overprovisioned. As you may expect, there’s an upper limit to the scalability of this approach and after a certain point it’s both risky and impractical.
The New World
Scaling a system requires reevaluating past design decisions and in some situations rebuilding the parts that no longer meet your requirements. We decided this was one of those cases and thus the pipeline needed some re-architecting. Stepping back, the purpose of this component is to accurately ingest logs in as close to real-time as possible. We’ll break this process into two parts: log file ingestion and log processing.
Coordinating the ingestion step is the responsibility of the “Leader,” which acts as a scheduler of sorts. The Leader is responsible for figuring out which log files need to be pulled and "assigning" the log files out to be processed. Each CDN pushes log files at different intervals and both the number and size of these files can vary widely. Processing consists of downloading the files, parsing each one according to a series of CDN-specific logic, and emitting the individual log records in a normalized Protobuf format to Kafka for the next node in the pipeline. The instances performing the processing will be called “Workers.” With all that in mind, here’s the high-level architecture:
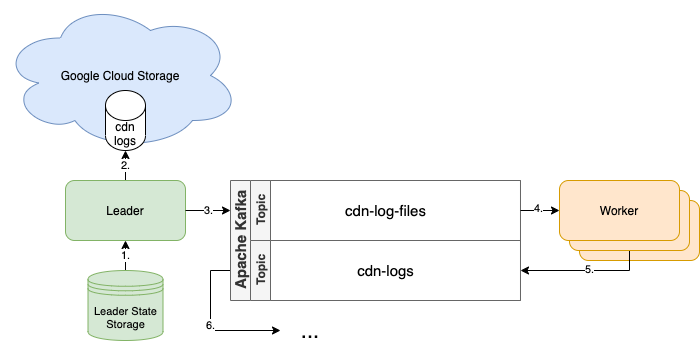
Not too bad, right? It's possible to use this same deployment for all CDNs or repeat this structure for each CDN to manage them independently. Here's a quick rundown of what's going on:
- The Leader state is very small, chiefly consisting of a representation of the time up to which we’ve processed all of the logs. We maintain this in a storage system separate from the application so that it can be safely restarted.
- As mentioned, it's the Leader's job to go figure out what log files need ingesting. It accomplishes this by looking at the remote source (GCS buckets) and filtering for any files that match the time we're interested in.
- Each file is written as a separate message to a Kafka topic (cdn-log-files).
- One or more Worker processes are reading files off of this topic and parsing each individual log line specific to that CDN.
- Each parsed log line is individually written to another Kafka topic (cdn-logs).
- Any downstream services can read from this topic and do additional processing or aggregate and emit the records to another source.
One thing to note is that while Kafka is superb for processing streams of data it doesn't necessarily excel as a task queue. We're using it in this situation because it avoids incorporating yet another external system, we have loose ordering guarantees, and we have the ability to replay records in an emergency. Above all else, it also allows us to leverage the same EOS guarantees across the entire pipeline. All in all, we’ve found this to be easier to manage operationally and can scale indefinitely.
The Case for Kafka Transactions
Glossing over the details for a minute, let’s say we’ve implemented this design. We have a Leader producing records to a topic containing the log files that need processing and many Workers consuming from those topics and producing the individual log messages. To best understand where Kafka transactions fit into this paradigm, we have to examine what happens when things go wrong.
There are two important consumer settings that non-transactional consumers are typically concerned with: the session and rebalance timeouts. The session timeout specifies the maximum amount of time a consumer can go without sending a heartbeat before the broker considers it “dead.” The rebalance timeout is a limit on how long a consumer can take to finish its current batch of work and commit its partition offsets in the event of a consumer group rebalance, which occurs whenever a consumer joins or exits the group. At a high level, exceeding one or both of these timeouts will cause the Kafka broker to “fence” that consumer and it will no longer be able to commit its offsets back to the broker. Thus no forward progress can be made on that partition and if left undetected the consumer will endlessly spin on errors, reprocessing the same records all the while.
Given that certain CDNs grow their log files vertically instead of horizontally, during periods of high traffic those log files can get quite large and may take a long time to process. During normal operations this is fine, but what happens if a worker crashes due to resource exhaustion, node failures, or any other unexpected and unrecoverable error? Since this causes a consumer to leave the group, this means that any current consumers have until the rebalance timeout to finish their current work before the partitions are redistributed. And if they can’t? Congratulations, every consumer in your group has been fenced! Even if the consumers terminate and new ones spin up to replace them, the constant shuffling of consumer group membership causes what we commonly refer to as a “rebalance storm” and none of the consumers will be able to make progress.
To exacerbate the issue, previously all of our producers and consumers were built using the popular Sarama Kafka client library. It’s a great library but as of version 1.27.2 it has a major caveat to the way it manages sending heartbeats to the broker. It does this in a separate looping goroutine as you may expect, however presumably due to some old Kafka behavior (see KIP-62) in the event of a rebalance it stops heartbeating. Thus the session timeout functionally becomes the limit on the amount of time consumers have to complete their work before the broker considers them dead and fences them. Sarama allows you to raise this value but once you exceed 30 seconds you must also increase the library’s socket timeout, which has different consequences.
So say this nightmare situation has occurred and all of our consumers are stuck, unable to commit their partition offsets and consume new records. They’re still able to retrieve and process records, they just can’t make any actual progress on the partitions. That’s bad. But what’s really bad is that these consumers are still producing log records to a downstream topic on every loop. If it’s a large log file and the consumer fully processes it before erroring 100 times in a row, it’s now written 100 times more records than it should have. Now your billing data is ruined and you have to clear out and reprocess all of the known bad data, including all of the downstream consumers. If you hadn’t guessed already, this has caused us more than one sleepless night. What if there was a way to prevent all of those records from being written until the corresponding offsets for the file have been written to Kafka?
Adopting Transactions
If you aren't familiar with the use case for Exactly Once Semantics and how Kafka solves this, Confluent has a great series about it. But before we go any further, it's worth calling out that Kafka transactions are not like RDBMS transactions and thinking of them as such will lead to pain and/or confusion. I say this because there is a different set of questions, including but not limited to: how should I assign transaction IDs to my producer(s)? What partitioning strategy should my producers use? What should my consumer group rebalance and transaction timeouts be? What strategy should my consumers use to join consumer groups? Thankfully a good library will make all of this easily configurable but it all requires research and testing so that you're confident your Kafka infrastructure is providing you the right guarantees.
When it comes to libraries for Golang, I'm afraid the alternatives are rather limited. We ended up going with Franz-Go and have been very happy with it. The library is well documented and the author does an excellent job of keeping it up to date with Kafka Improvement Proposals, feature requests, and bug fixes. If you're like us and are coming from an existing Kafka library like Sarama, it's an enormous time-saver to hide the details of the library behind your own interface or other abstraction. Implementing this in an internal library of some kind makes it easier to switch other producers and consumers as needed and saves large refactoring efforts down the line if the requirements change.
To illustrate how we can save ourselves from the catastrophic scenario described above, let’s look at some sample code. For the sake of demonstrating what's going on, we're going to use the Franz-Go library directly rather than encapsulating it as we do internally. Note that these examples are using version 0.8.6 of the library.
Ingesting Log Files
"Ingestion" refers to steps 1-3 in our design diagram, which revolve around the idea of one or more Leader process(es). This is the main leader entry point that initializes kgo and starts up the run loop.
func startLeader(ctx context.Context, brokers []string, logsTopic string) {
// Set up the kgo Client, which handles all of the broker communication
// and underlies any producer/consumer actions.
client, err := kgo.NewClient(
kgo.SeedBrokers(brokers...),
kgo.TransactionalID(generateProducerID()),
kgo.DefaultProduceTopic(logsTopic),
)
if err != nil {
log.Fatalf("failed to initialize Kafka client: %v", err)
}
defer client.Close()
for {
select {
case <-ctx.Done():
return
default:
// This could be wrapped in a retry loop to handle situations like system outages more gracefully.
if err := run(ctx, client); err != nil {
log.Printf("error running leader: %v", err)
}
}
}
}As mentioned earlier the most important part of the Leader state is its timekeeping, or in other words the representation of time that reflects what files have already been processed. The reason this is maintained separately is because wall-clock time won't work as system downtime or other delays may result in our skipping logs, not to mention it deprives us of the ability to re-process logs from some point in the past. The idea is that on every run, the leader will fetch the current timestamp and use it to obtain a list of files we need from the remote (for instance by using a fast prefix query in GCS if the filenames include time) and those are what we write to Kafka. It's advantageous to make this human-readable so that it can be edited in case of emergencies; a simple RFC3339 timestamp would work just fine.
Here's the run method being called in a loop above (note that some methods are stubbed out for brevity):
// You'd likely want to tune this to something more appropriate for your application.
const transactionTimeout = 3 * time.Minute
func run(ctx context.Context, client *kgo.Client) error {
// Load the leader's state from remote storage (i.e., the next time to process).
timestamp, err := readCurrentLeaderState(ctx)
if err != nil {
return fmt.Errorf("error loading current leader state: %v", err)
}
// Wait until there is log data available for the time we want.
delayUntil(ctx, timestamp)
// Obtain the list of files to process from the remote source (like GCS).
files, err := readFileListFromSource(ctx)
if err != nil {
return fmt.Errorf("error determining files to process on remote: %v", err)
}
// Start the transaction so that we can start buffering records.
if err := client.BeginTransaction(); err != nil {
return fmt.Errorf("error beginning transaction: %v", err)
}
// Write a message for each log file to Kafka.
if err := produceMessages(ctx, client, files); err != nil {
if rollbackErr := rollbackTransaction(client); rollbackErr != nil {
return rollbackErr
}
return err
}
// Advance the timestamp to the next interval to "complete" this batch.
if err := updateLeaderState(timestamp); err != nil {
if rollbackErr := rollbackTransaction(client); rollbackErr != nil {
return rollbackErr
}
return err
}
// Commit the log file "task" messages to Kafka to complete the batch. Note that
// we're running in autocommit mode by default, which will flush all of the
// buffered messages before attempting to commit the transaction.
if err := client.EndTransaction(ctx, kgo.TryCommit); err != nil {
if rollbackErr := rollbackLeaderState(timestamp); err != nil {
return rollbackErr
}
return fmt.Errorf("error committing transaction: %v", err)
}
return nil
}Producing messages with Franz-Go is an asynchronous operation, so we call Produce for each message and then wait for the callback functions we provide to be called indicating whether or not the write was successful. In our case we want to cancel the batch if any errors occurred, so we use the FirstErrPromise helper that will wait for all records to flush and then return the first error encountered (if any).
func produceMessages(ctx context.Context, client *kgo.Client, files []string) error {
// Send the messages as fast as possible but make sure none of them failed before returning.
var errPromise kgo.FirstErrPromise
for _, filename := range files {
r := kgo.StringRecord(filename)
fmt.Printf("writing record: %v\n", r)
client.Produce(ctx, r, errPromise.Promise())
}
// Wait for all of the records to be flushed or for an error to be returned.
return errPromise.Err()
}As you may have noticed, combining a Kafka transaction with an update to an external system brings us to the notoriously difficult problem of trying to manage state consistently across distinct distributed systems. For example, what happens if the Kafka transaction fails to commit and then it fails to revert the update to external storage? There are mitigation strategies here like using highly available storage, adding retry logic, and so on but the semantics are application-dependent and important to consider. At least the code is simple:
func rollbackTransaction(client *kgo.Client) error {
// Background context is used because cancelling either of these operations can result
// in buffered messages being added to the next transaction.
ctx := context.Background()
// Remove any records that have not yet been flushed.
client.AbortBufferedRecords(ctx)
// End the transaction itself so that flushed records will be committed.
if err := client.EndTransaction(ctx, kgo.TryAbort); err != nil {
return fmt.Errorf("error committing transaction: %v", err)
}
return nil
}It's dealer's choice as to how many of these you want to run in parallel, though running multiple means that you need a strategy for avoiding enqueuing the same log file multiple times. As heavy Kubernetes users, in our experience it's been most effective to run one highly instrumented Leader per-CDN with built-in retry behavior since K8s will ensure a Leader pod is always running and on-call is alerted quickly in the rare situations where something goes wrong.
Processing Logs
"Processing" is the last half, steps 4-6 from our diagram. It's a pretty run of the mill ETL-esque structure where we consume records, transform them, and emit the results. Given our output is also heading to Kafka, transactions are particularly helpful here because if we're processing a bunch of files and we do not want to complete the transaction for any reason (say due to errors or consumer group rebalances), aborting the buffered records and ending the transaction means that no records will be made available to consumers and those offsets will be left in place. Thus, they can be retried or picked up by a different consumer without duplication.
Franz-go just so happens to provide a consumer group session implementation for exactly this use case called GroupTransactSession. This implementation abstracts away most of the details for consuming and producing records as part of the same transaction
The basic setup is similar to the Leader:
func startConsumer(ctx context.Context, brokers []string, consumerGroup, taskTopic, logsTopic string) {
// Join the consumer group and get a GroupTransactSession from the client.
sess, err := kgo.NewGroupTransactSession(
kgo.SeedBrokers(brokers...),
kgo.TransactionalID(generateTransactionID()),
// Required for consumers reading records committed in a transaction.
kgo.FetchIsolationLevel(kgo.ReadCommitted()),
// Consume from the log tasks topic.
kgo.ConsumerGroup(consumerGroup),
kgo.ConsumeTopics(taskTopic),
// Produce the individual log records to the logs topic topic.
kgo.DefaultProduceTopic(logsTopic),
)
if err != nil {
log.Fatalf("failed to initialize Kafka client: %v", err)
}
defer sess.Close()
// taskTopic is the topic to which our Leader is producing.
consume(ctx, sess, consumerGroup, taskTopic)
}We're also going to use a loop here that just runs until cancelled. This code joins a consumer group and continuously fetches records for its assigned claims with GroupTransactSession handling the addition or removal of partitions behind the scenes.
func consume(ctx context.Context, sess *kgo.GroupTransactSession, consumerGroup, taskTopic string) {
for {
// Poll for records across the partitions assigned to this consumer. The Fetches object
// returned has an Errors() method that should be checked in case there were errors
// reading from one or more partitions.
fetches := sess.PollFetches(ctx)
for _, err := range fetches.Errors() {
log.Printf("error fetching from topic %s on partition %v: %v", err.Topic, err.Partition, err.Err)
continue
}
select {
case <-ctx.Done():
return
default:
}
// Start the transaction; errors here are likely non-recoverable.
if err := sess.Begin(); err != nil {
log.Fatalf("error beginning transaction: %v\n", err)
continue
}
// Process every message across all assigned topics and partition claims. We use a shared
// FirstErrPromise that will collect any errors for us to check.
var errPromise kgo.FirstErrPromise
fetches.EachRecord(func(r *kgo.Record) {
handleRecord(ctx, sess, &errPromise, r)
})
// Fail the batch if we encountered any errors writing messages.
shouldCommit := true
if err := errPromise.Err(); err != nil {
log.Printf("error producing record: %v", err)
shouldCommit = false
}
// End the transaction, either committing the records or aborting in the case
// of flush errors or a consumer group rebalance. Note the use of the background
// context to avoid cancellations that leave the client in a bad state.
if _, err := sess.End(context.Background(), kgo.TransactionEndTry(shouldCommit)); err != nil {
log.Printf("error ending transaction (commit=%t): %v", shouldCommit, err)
}
}
}Handling the contents of the file (i.e. transforming each line into a log record) is simple; just produce a message for each long line you want to emit. The same promise is used for all files in this example so that any errors will abort the entire batch, regardless of how many files are in flight.
func handleRecord(ctx context.Context, sess *kgo.GroupTransactSession, errPromise *kgo.FirstErrPromise, r *kgo.Record) {
// Produce() is asynchronous, so buffer all of the logs and let the caller Flush() them.
// Any errors will be reported to the promise.
logFile := string(r.Value)
for logMessage := range processLogsInFile(logFile) {
record := kgo.StringRecord(logMessage)
sess.Produce(ctx, record, errPromise.Promise())
}
}These files may take a little while to complete by typical Kafka consumer standards so it's advantageous to add some parallelism. What you might do is fan out a goroutine per partition "claim", with that goroutine sequentially processing every message in the list of messages fetched by the consumer. This means we remain consistent with Kafka's partition ordering guarantees while still being able to speed up the processing when a consumer is fetching from multiple partitions.
Consumers built in this way can be easily scaled up or down safely with Franz-Go managing the messy details of the consumer group and concurrency improving the message processing performance. This example code is relying on automatic flushing that's enabled by default (turning it off is a producer option) and this can be tuned for additional performance. There are other configuration options that may be relevant for your application and I encourage you to to check out the Franz-go examples and documentation.
Conclusion
This approach has helped us keep pace with Mux's rapidly increasing traffic patterns and is currently cruising while handling hundreds of thousands of logs per minute and growing. The system is very stable and not only self-recovers from most issues but also easily handles our largest customer events with loads of headroom to grow alongside the product.
Hopefully some of these ideas are helpful and even if you have a different use case, Kafka transactions are an incredibly powerful tool and an increasingly essential component of a system that's ready for scale.


