
It shouldn't come as a surprise that Mux Data works with large amounts of data. We process millions of video views each day. The majority of those views will transmit multiple beacons. A beacon is a collection of data representing details about the video playback experience. We must accumulate beacons for every video view until it's ready to be finalized.
Beacons are written to a durable log until they’re ready to be processed and associated with a video view. Until recently, we used the Kinesis service from Amazon Web Services (AWS) to store beacons. Kinesis is a sharded high-availability log hosted and supported entirely by AWS. Kinesis had worked well for over 3 years, but had proven expensive and difficult to scale in response to sudden changes in load.
We opted to use the open-source Apache Kafka distributed log for the Mux Video service to process CDN access logs and communicate between services. Kafka is an open-source distributed log that's functionally similar to Kinesis. We figured the time was right to replace Kinesis with Kafka for handling Mux Data beacons. This would help us unlock significant cost savings, cloud portability, and greater control over performance.
This post will discuss some of the engineering work we performed in order to make the move to Apache Kafka.
Kafka Primer
First, some background on Apache Kafka.
Kafka is a highly-available, distributed, ordered log:
- Highly-Available: Data in Kafka can be replicated across multiple machines, meaning that the failure of a single machine can be tolerated
- Distributed: Writes and reads from Kafka are distributed across multiple machines (brokers). Capacity can be increased by scaling horizontally (adding more Kafka brokers) and/or vertically (increasing the CPU & storage resources for the existing Kafka brokers).
- Ordered: Writes to a Kafka topic are stored in the order they were made. Reading from a Kafka topic partition should give deterministic, repeatable results.
Why would someone use Kafka? Kafka is great for storing ordered data that continues to be generated over time. It's not a database; it's the temporary storage system for data that might eventually end up in a database.
Popular use-cases include:
- Internet-of-Things data streams
- Banking transactions
- Web site traffic logs
- Video analytics beacons :)
A Kafka cluster can consist of multiple brokers. Each broker is responsible for hosting some or all of the topic partitions in the cluster.
Think of the broker as a filing cabinet, the topics as drawers, and the folders within each drawer as partitions.

Data within each drawer (topic) is organized into folders (partitions). Depending on the access pattern, you might want to divide the topic into more or less partitions. Using the filing cabinet analogy, you could have a filing cabinet with alphabetically-sorted files, split in 4 folders/partitions (A-F, G-J, K-R, S-Z), or 26 folders/partitions (A, B, C, etc.) With a Kafka consumer group there can only be one consumer reading from a partition at a time. So, if you had only 4 partitions, then only 4 consumers could read at a time. With 26 partitions, you could potentially have up to 26 simultaneous consumers. The number of partitions determines how many consumers can read from the topic, which in turn affects the maximum throughput of the topic.

If a topic is configured to maintain multiple replicas (highly recommended!) then Kafka will keep copies of the data on multiple machines. How many copies are maintained is controlled through the topic replication factor. More copies means a higher tolerance for failure, but it also increases the storage costs and overhead associated with keeping the copies synchronized. Continuing the filing cabinet analogy, this is like having multiple people devoted to the task of copying the data to identical filing cabinets, all day every day!
If one of the filing cabinets were to catch fire, you could just switch to one of the replicas. Similarly, Kafka will automatically switch to brokers with replicas of the incinerated topic partitions.

Producers are any software that writes to a Kafka topic. They always append to a topic partition (e.g. always add files to the back of the filing folder), and the ordering of messages is guaranteed by Kafka. There can be any number of producers. When a producer determines it needs to write to a particular topic partition, it will write directly to the Kafka broker that’s the current leader for the partition. If the partition leader changes, perhaps because the Kafka broker was stopped, then the producer will learn the new partition leader from the cluster controller and start writing to it.
Consumers are any software that reads from one or more topics, possibly in a coordinated manner as member of a Kafka consumer group. When you have multiple consumers all working together in the same consumer group, a consumer group leader (one of the consumers chosen by the Kafka broker working as the consumer group coordinator) will create a plan for the consumers to consume from all the partitions of the topics they specified at the time of joining. There can only be one consumer on a topic partition within a consumer group; a consumer can consume from multiple topic partitions simultaneously (e.g. one person can pull multiple folders from the filing cabinet to work on).
Kafka tracks the read-offset of the consumer-group on each topic partition. If a consumer wishes to leaves the group, then it will finish up its work and commit its offset, a consumer group rebalance will be triggered, and the consumer group leader will find a new consumer for the unclaimed topic partitions. A rebalance is also triggered when a new consumer joins the group, possibly leading to a better distribution of partition assignments.

A real-life consumer-group, accessing files in a somewhat coordinated manner (https://www.arpc.afrc.af.mil/News/Art/igphoto/2000915523/mediaid/750332/)
Stateful Processing of Mux Data Beacons
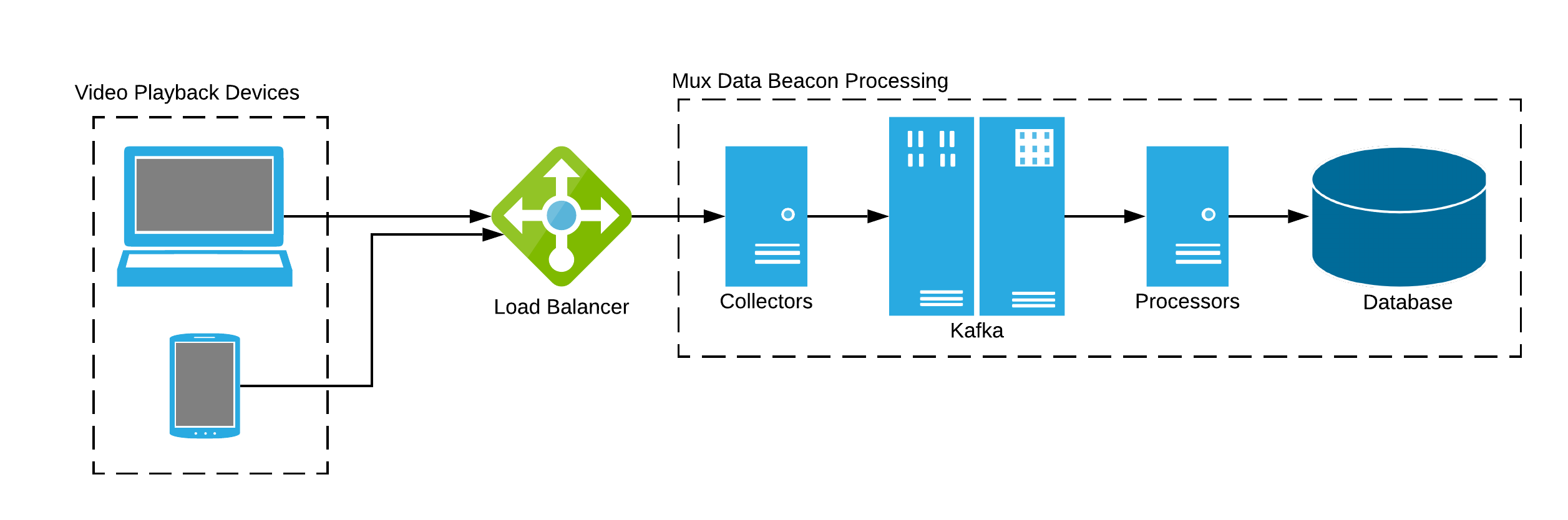
Beacon processing is performed by Collectors (producers) and Processors (consumers). A Kafka cluster sits between groups of Collectors and Processors, with multiple partitions to allow for highly-parallelized processing of video views:
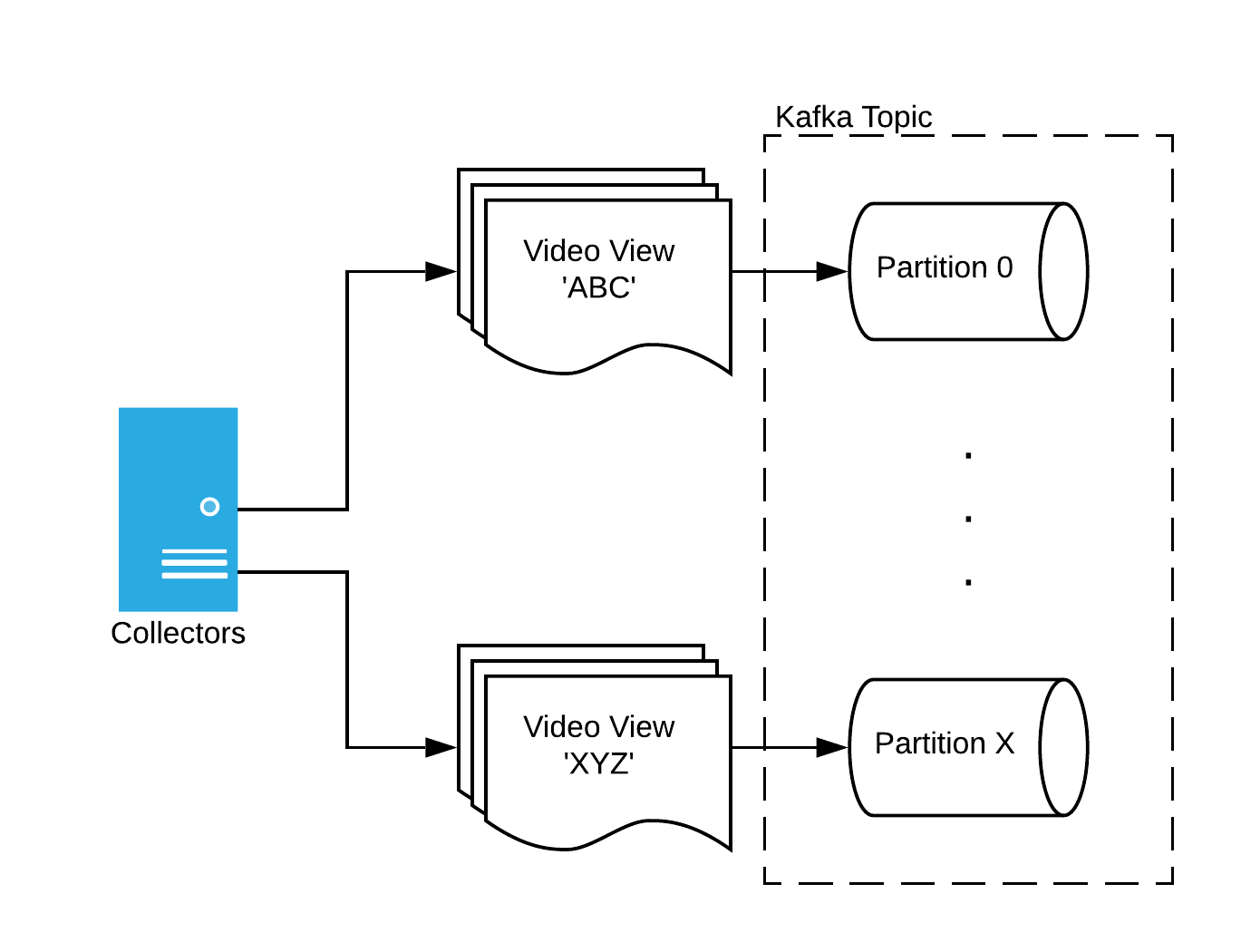
Collectors
Mux Data has a variable number of collectors (lightweight Golang HTTP servers) that receive video view beacons, perform some minimal processing and format-conversion, and write the beacons to Kafka topics. The number of collectors running is scaled automatically in response to CPU load.
Beacons are hashed to a specific topic partition using a composition of the Mux customer identifier and the video view ID. Each beacon associated with a view will include the same video view ID. This ensures that all of the beacons for a given video view will land on the same Kafka topic partition.
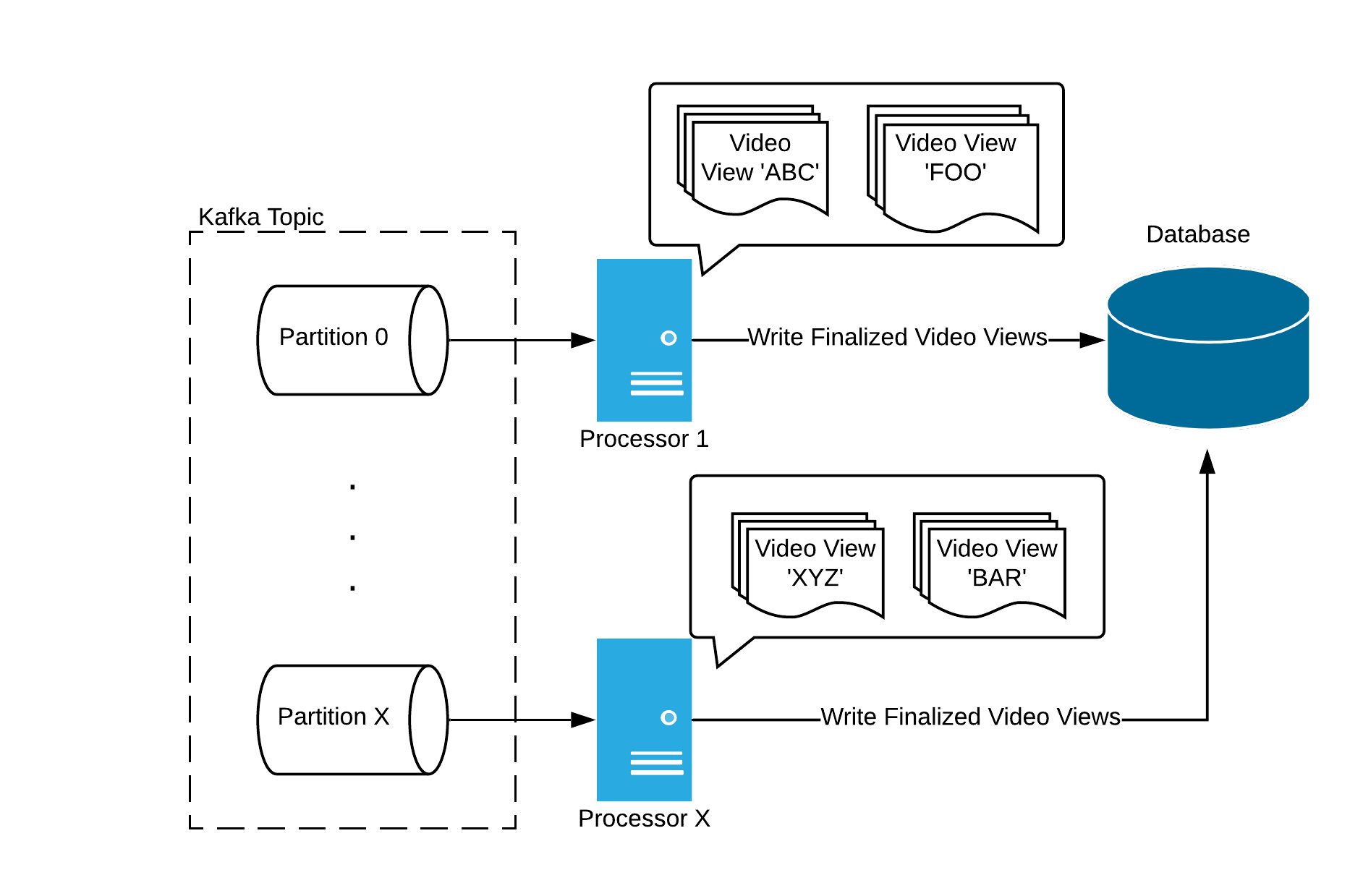
Processors
We’ve got a large number of Processors (100+) reading video view beacons from Kafka. A Processor accumulates beacons for each view it's tracking until the view ends or is automatically finalized after a period of inactivity. In practice, finalized views are written to another Kafka cluster before being written to the database, but that doesn't factor into the challenge of accumulating state addressed here.
As was mentioned earlier, the Kafka consumer group will automatically rebalance when a consumer joins or leaves the group. This triggers partition reassignment within the consumer group.
Partition Assignment Schemes
We’ve been using Shopify's Sarama Kafka client library for Go, which has historically only supported two partition assignment schemes:
- Round Robin
- Range
It’s impractical to use these assignment schemes for stateful processing at scale. Any time a rebalance is performed, the consumer assigned to each topic partition could change. This would lead to each Processor flushing its state to a durable, distributed cache so that processing can be resumed on a different Processor. This would be highly disruptive.
We needed a way to preserve Kafka consumer group assignments as much as possible during consumer-group rebalances.
Sticky Partitioning
The official Kafka client for Java recently added support for a partition assignment scheme called “Sticky Partitioning” through KIP-54 and KIP-341. This scheme works by having the Kafka consumer group metadata serve as a record of which consumer-group-session was associated with each topic partition at the end of a rebalance. When a subsequent rebalance happens, any consumer group sessions that are still active are allowed to keep as many of their topic partition claims to the extent that overall balance is maintained.
I took this opportunity to add a Sticky Partition assignor to the Sarama Kafka client library.
Mux has long advocated contributing to open-source projects. I received a lot of excellent feedback from contributors to the Sarama project (thank you, varun06 and twmb!). My pull-request was merged into the Sarama master branch in September 2019 after a month of review and testing.
How Mux Uses Sticky Partitioning
Each Processor is capable of running multiple Processor "cores", where a core consumes from a Kafka topic partition. When a Kafka consumer group rebalance occurs and a new claim is obtained, a new Processor core is created to process beacons from that topic partition. Similarly, when a claim on topic partition is released, the Processor core is flushed and shut down.
We use the Sticky Partition assignor in Sarama to preserve partition claims across Kafka consumer-group rebalances. Minimizing the impact of rebalances is critical for our deployment and error-recovery processes. Imagine having dozens of Processors switching up their partition claims each time a Processor is started or stopped - chaos!
The Mux Data Processors run as Kubernetes deployments, each with a desired number of replicas. We upgrade the Processors by patching the deployment, typically with just a change to the Docker image tag. Kubernetes begins terminating one Processor ("Processor X") by sending it a signal to shutdown with a 2 minute grace period. Meanwhile, a new Processor pod ("Processor Y") will be created and join the Kafka consumer group. The act of joining the consumer group triggers a rebalance, but the consumer-group leader will use the sticky-partitioning scheme to ensure that topic partition assignments remain constant until the old Processor pod leaves the group. At this point we’ve got (desired # of replicas) + 1 Processor pods in the Kafka consumer group.
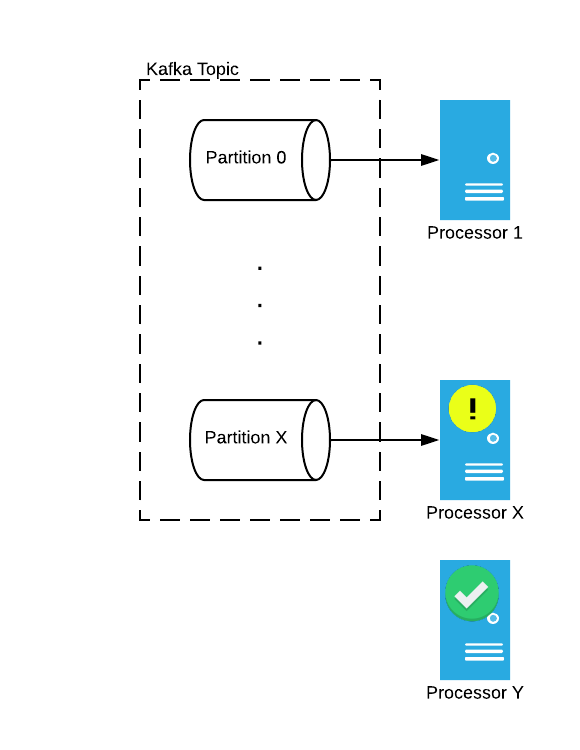
When the old Processor pod finishes flushing its state to durable storage and leaves the Kafka consumer group, a rebalance is triggered and the new Processor pod takes over the partition claim, loads the partition state from durable storage, and begins consuming from the partition. All other Processors keep on truckin’ with the same partition claims. Repeat this for potentially hundreds of Processors.
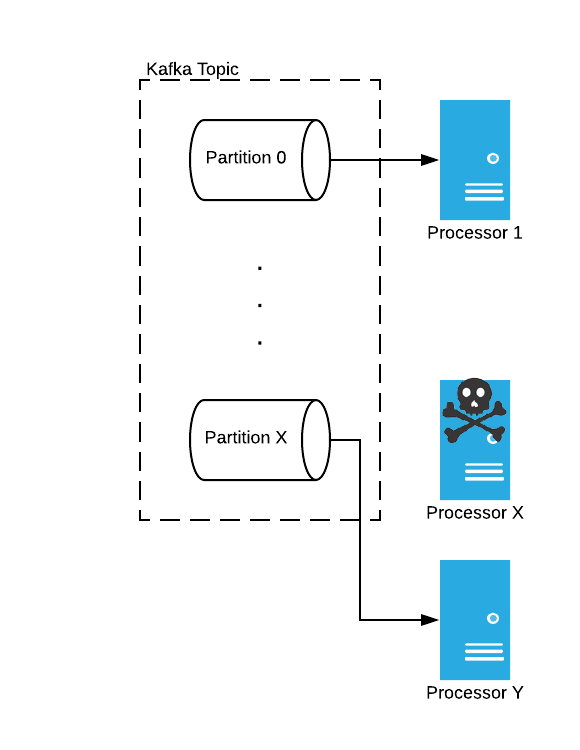
The Sticky Partition assignor has made our transition from Kinesis to Kafka smooth and reliable. We were also able to reduce the overall complexity of the system. Consumer partition assignments are tracked by Kafka through consumer-group metadata; previously, we had to track Kinesis shard claims in Consul, which worked fine, but was nowhere near as robust as what Kafka offers through Sticky Partitioning and was wholly bespoke (in a bad way).
Additional Findings: Watch the Consumer Group Session Timeout
We run several beacon processing clusters, complete with their own set of Collectors, Processors, and Kafka cluster. Some clusters handle relatively little traffic, while others handle a whole lot.
Our initial rollout was performed with low-volume clusters that had relatively few active video views with beacons being processed. The shutdown sequence for a Processor includes serializing all of its in-flight video views and writing them to durable storage (Riak). The shutdown sequence was completing on the order of a few seconds.
When we began upgrading the Processors in some of our more active clusters, we noticed that Kafka topic partitions were being reassigned before the old Processors had finished writing their state to Riak. This is very bad, since it could lead to video views from the old Processors not resuming cleanly on the new Processor (e.g. split views).
After some investigation, the problem was painfully obvious.
The Sarama client uses a default Kafka consumer-group session timeout of 10 seconds. When a consumer stops consuming, it has that much time to finish up processing before the Kafka consumer-group-coordinator considers it dead and triggers rebalancing.
Our heavily loaded Processors were unable to flush their state to Riak in 10 seconds or less, so their claims were being automatically reassigned without them cleanly leaving the consumer-group before the session timeout elapsed. This did not occur on the low-volume clusters because their state was serialized in far less than 10 seconds.
The short-term fix was to increase the Kafka consumer-group session-timeout in the client from 10 seconds to 60 seconds. This comes with the caveat that it will take up to 60 seconds to detect a Processor that died unexpectedly and trigger a rebalance. We will consider parallelizing the serialization of state to quicken the shutdown sequence with the goal of reducing the session timeout.
Conclusion
We've had great experiences with Kafka in both our Mux Data and Mux Video products, and will continue to make it a central part of our infrastructure. Performing stateful processing of Mux Data beacons with minimal disruption during Processor stops and starts was critical, and the flexibility of Kafka and the Sarama Kafka client library made this relatively easy to accomplish.
If you're looking for a video analytics service that can operate at Super Bowl scale, then Mux Data is meant for you. And if our work with Kafka and Go sounds interesting, then I encourage you to check our Jobs page for openings!


