
Mux will be represented at the Scale by the Bay conference over November 15-17, 2018 at Twitter HQ in San Francisco. The following is a preview of Scott Kidder’s talk on the stream-processing system built by Mux to handle large volumes of video-streaming logs.
Mux Video makes delivering Internet video as simple as issuing a few REST API calls. Our customers have described it as “Twilio for video”, which is exactly what we’re aiming for. We handle many of the difficult tasks associated with delivering video and offer straightforward utility billing.
Utility billing requires us to track the number of minutes of video delivered using access-logs from our Content Delivery Network (CDN) partners.

David R. Tribble, CC BY-SA 3.0
All Mux videos are currently served using HTTP Live Streaming (HLS). HLS works by dividing a video into discrete MPEG-TS chunks of roughly the same duration (e.g. 5 seconds). An M3U8 rendition manifest lists all of the chunks in the order they should be played. An M3U8 master manifest lists the available rendition manifests; a rendition manifest represents a certain quality level and configuration (e.g. video resolution, bitrate, codec). Shifting between quality levels is accomplished by requesting a different rendition manifest and resuming from the same chunk number. Video playback is typically initiated by requesting the master manifest, selecting the appropriate rendition manifest for the device and network conditions, then retrieving & playing the video chunks in order.
Let's look at some of the challenges associated with processing video access logs at scale.
Challenges
“Netflix is a log-generation application that happens to stream videos”, Werner Vogels, Amazon CTO
Scalable Log Storage and Processing
Video chunks are highly cacheable and represent the bulk of our storage and transfer costs, so we aggressively cache them at the CDN edges to reduce requests to our origin. However, an access log record is generated and sent to our log collection endpoints regardless of whether a video chunk was served from CDN cache or via a request to the origin. This leads to the obvious challenge of needing to process a potentially massive number of log records without warning. A viral video with a high hit-ratio at the CDN still generates a large volume of access logs that must be processed to support billing and monitoring of our CDNs.
Also, the access-logs must be written to a durable, fault-tolerant log that can easily grow with increased log volume and access. Automated retention and deletion of logs are desirable.
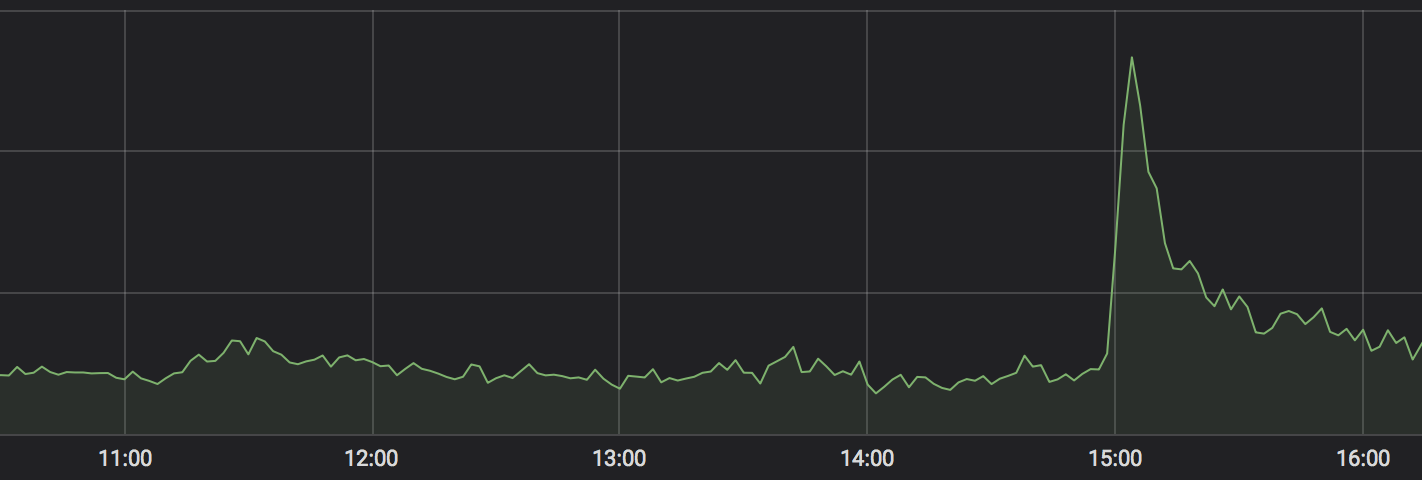
Unexpected load spikes must be considered normal
Support for Multiple CDNs
Our CDN partners use different mechanisms to deliver access logs. Some CDNs use Syslog to continually push records, typically achieving less than one minute of delay from the time of the original request. However, other CDNs use HTTP push mechanisms where they’ll issue an HTTP POST and can take several hours to fully deliver all access logs. Despite this shortcoming, these CDNs are worth considering; in some cases, they offer a larger number of Internet points-of-presence (POPs) around the world, better overall network performance, or more favorable pricing. So, our system that calculates video delivery minutes must be capable of handling records that are several hours late and produce consistent, deterministic results.
Avoid a Thundering-Herd against the Asset Database
The raw log-records must be enriched with information about the associated video asset and network information (client ASN & geographic details). Enriched log records must be written to a second log configured with a longer retention period to support data mining and billing. We must ensure that enrichment of logs with asset details doesn’t overload the asset database.
Databases are expensive, but caching servers are cheap. This is nothing new. The following story from Brad Fitzpatrick, creator of LiveJournal, Memcached, and many other wonderful things, tells how he came up with the idea for Memcached in 2003:
"I was in my shower one day. The site was melting down and I was showering and then I realized we had all this free memory all over the place. I whipped up a prototype that night, wrote the server in Perl and the client in Perl, and the server just fell over because it was just way too much CPU for a Perl server. So we started rewriting it in C."Peter Seibel. Coders at Work: Reflections of the Craft of Programming
Let's not have our databases meltdown.
Exactly-Once Stream Processing
The application that computes media-usage totals must evaluate an access-log record exactly once (i.e. no double charging). We compute hourly usage by accumulating the duration of all successful media deliveries by customer environment. It is imperative that an access-log record is processed only once. This has implications on the upstream log-enrichment process and its handling of unexpected restarts.
Solution
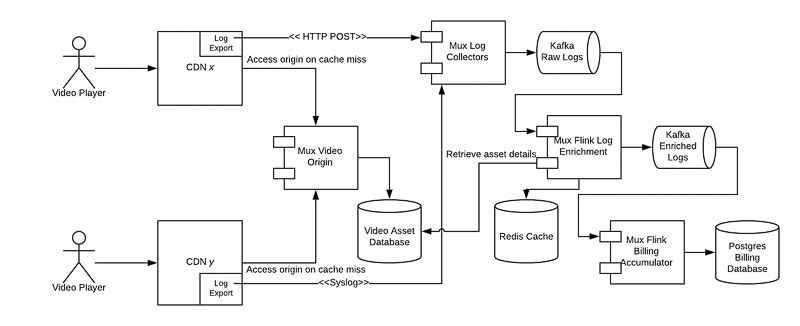
Log Collectors
We began by ensuring that we can capture and persist every access log record. This is accomplished with only a few collectors initially but must scale to many more collectors in the future as service usage increases. Lightweight stateless log collectors receive CDN logs over Syslog or HTTP POST, build up a Protobuf message that conforms to an internal schema, and write batches of Protobuf-encoded CDN logs to a Kafka topic. This scales by simply increasing the number of collectors running at the edge, and increasing the number of Kafka brokers and/or topic partitions to increase write throughput. The log collectors are written in Go, and run a different handler for each log-delivery method (e.g. Syslog, HTTP).
Apache Kafka
The access-logs Kafka cluster consists of multiple Kafka brokers that host a subset of the partitions associated with the cluster topics. All log-record topics have a replication-factor of 2, ensuring that every partition has an in-sync replica on a different broker that can assume the lease in the event that current leaseholder disappears. If the Kafka brokers become CPU-bound, we can introduce more brokers to the cluster and update the partition map to distribute the load and storage more evenly.

Stream Processing with Apache Flink
With the collector and log-storage problems solved, we turned to the challenge of enriching the access-logs. We’ve used the Apache Flink stream-processing platform in our Mux Data product to process video-view errors for automatic alerting (see our earlier blog post for details). Flink applications scale horizontally with ease and integrate nicely with Apache Kafka with full support for Kafka transactions.
Our log-enrichment Flink application reads raw access-log records from a Kafka topic, then retrieves additional information about the corresponding video asset and rendition setting by querying a remote Redis cache; on a cache-miss, it’ll query the asset database and insert the response into Redis. The Redis cache helps shield the asset database from the thundering-herd problem. The log-enrichment app also looks up the network ASN and geographic information for the client address.

The enriched log-record is written to a second Kafka topic for enriched log-records as part of a Kafka transaction; this topic has a very long retention period on the order of months. The Kafka transaction is committed only after the Flink checkpoint (taken every 5 minutes) completes (see Flink two-phase commits), ensuring that an unexpected restart of the log-enrichment app produces a log record only once as part of a committed transaction.
The media-usage Flink app tallies up seconds of video delivered for each asset and customer environment in one-hour windows. Once a one-hour window is finalized, the results are written to a Postgres billing database. To address the problem of late records, we leveraged Flink’s built-in support for windowing of out-of-order messages. For instance, suppose we configured the Kafka consumer to support records arriving as much as 3 hours out of order; Flink will emit a watermark for a timestamp only after it receives an event with a timestamp more than 3 hours later. This delays the finalization of hourly billing windows until all CDN access-log records have been delivered. Furthermore, we use event-time processing, so we can process log-records faster or slower than real-time with identical results.
The Future
Our enriched access-log data has become a powerful resource for troubleshooting video delivery issues. There are many additional features that this data unlocks, such as dynamically selecting the optimal CDN for a network ASN based on observed performance, or identifying popular content that should have additional renditions transcoded and pushed to the CDN edge to reduce the load on the origin and provide a better user experience.
Conclusion
We’ve leveraged the Apache Kafka and Flink projects to build a log-processing pipeline that can scale as the Mux Video service continues to grow. We’ve got a lot of great plans for this data, and are excited to share this design and our experiences at the upcoming Scale by the Bay 2018 conference in San Francisco.



{kind=link}