Updated 8/4/21: We hit pause on audience-adaptive encoding. Read more.
When people watch videos online, their video quality is mostly dependent on their internet connection. Faster internet means better video. This is great for people with consistent high-speed connections, but those folks are still in the minority.
Instead, most people simply end up suffering through low quality videos; we accept it as a sad fact of life—like morning traffic or melting ice caps. It sucks, but it's going to happen.
However, at least for video quality, there might be a better way.
Enter Per-Title Encoding.
What is Per-Title Encoding?
Per-title encoding, also referred to as content-adaptive encoding, first gained widespread attention in a December 2015 article from Netflix’s tech blog. In that article, Netflix demonstrated impressive results by using bitrate-encoding ladders that were optimized depending on the type of video content. The optimal bitrate encoding ladder for a nature video differs widely from fast-motion action or sports videos. The shot below demonstrates how per-title encoding can lead to sizable quality improvements:

To find the optimal encoding ladder, known as the convex hull, Netflix had to:
- Run dozens of encodes per bitrate-resolution pair
- Find the VMAF1 associated with those encodes.
- Select the bitrate-resolution with the highest VMAF
This process can take hundreds of hours, depending on the length of the video and how optimized your VMAF implementation is. Also, the number of encodes required per video makes this cost prohibitive for anyone with a large content library.
Mux overcomes these limitations by replicating Netflix’s methodology with a deep learning model. This allows us to get very close to Netflix-level results with virtually no additional cost and minimal increase in processing time. We’re calling it Instant Per-Title Encoding.
Instant Convex Hulls through Deep Neural Nets

Waiting for a standard per-title encoding job to finish
Most current per-title encoding solutions attempt to analyze the complexity of a video by directly measuring the bits and pixels through capped CRF encoding. However, a human being can easily recognize the difference between high vs low complexity scenes by simply looking at a few frames of video.
For example, imagine we had two clips from a football game. A frame is taken from each clip as shown below.

Even with just one frame present, a human can instantly spot which video requires a high vs low complexity bitrate ladder. So, what would that bitrate ladder look like?
To answer that, imagine you were given a (very) long list of possible bitrate ladders with labels such as Football Game - Goal Line Touchdown and Football Game - Commentary. You simply choose the appropriate label that matches the video and use the associated optimal encoding ladder to maximize quality and/or reduce bandwidth.
What happens if both labels are present in a video? In that case, you would look at the distribution of those scenes and combine the bitrate ladders based on their relative screen time in the video.
Technical Details
Of course, this is an oversimplification of our process, but the technical details follow the same principle.
First we built a deep neural net trained on millions of videos across a diverse range of content. We were able to do this thanks to the publicly available YouTube-8M dataset. This dataset is geared towards video classification, but we can utilize transfer learning to repurpose it towards convex hull estimation.
Using the neural network trained on YouTube videos, we create a feature embedding for each video ingested into our system. The features are encoded into serialized objects called Tensorflow records, and we use these to create our convex hull dataset (our very long list of ladders and labels). Serializing large feature embeddings into TF records allows for more efficient training. As a result, we’re able to experiment and iterate on different model architectures in a shorter period of time.
Once the convex hull dataset is created, we train an LSTM recurrent neural network that outputs a vector representing the optimum encoding ladder. We compare these vectors to the ground-truth convex hulls, and fit the model using mean-squared-error as the loss function.
Depending on the user, we can deploy different versions of a model to fit the type of content being uploaded.
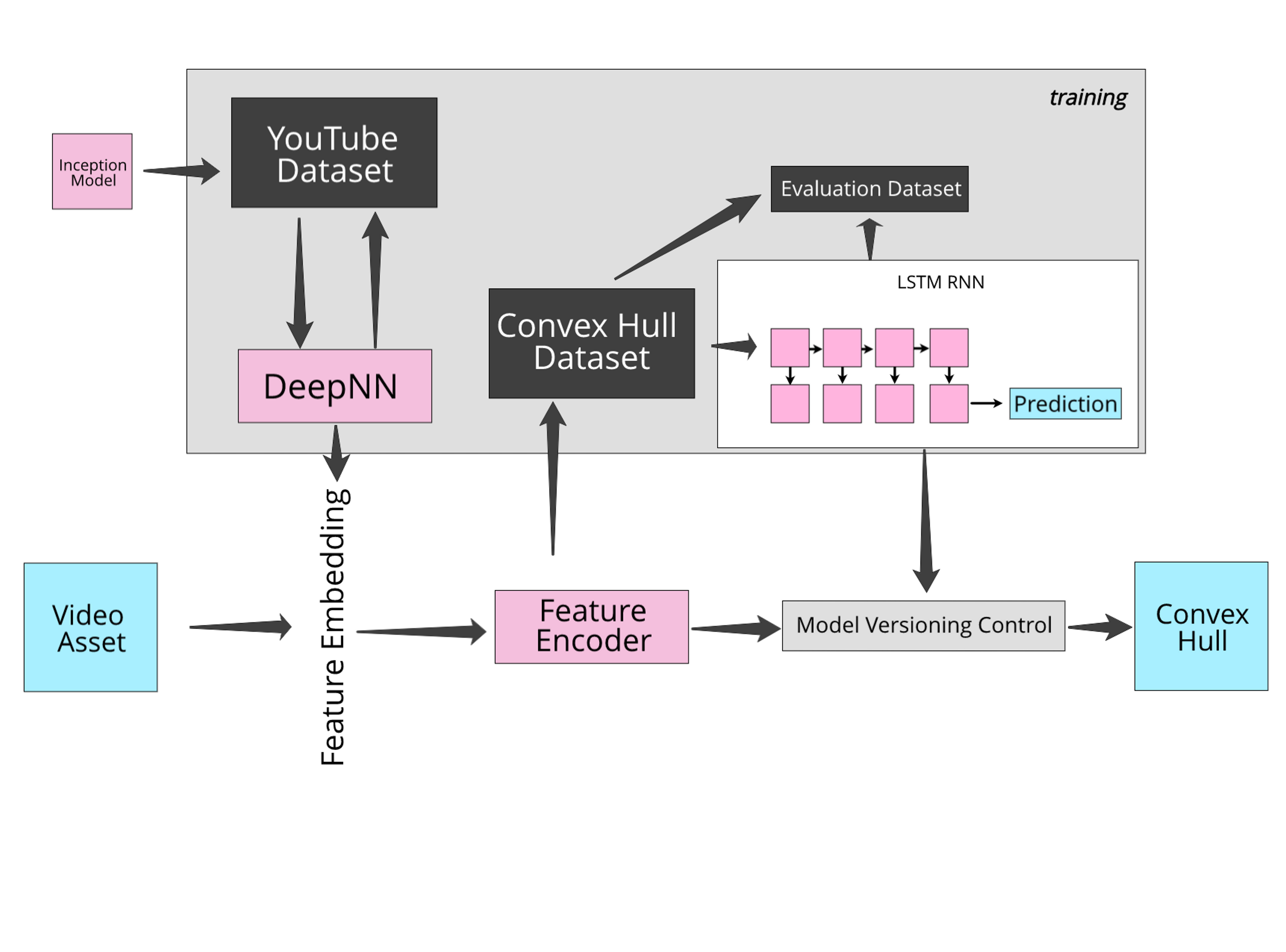
The final result is an end-to-end trainable network which converts videos to vectors and outputs an optimal encoding ladder. Using this process, creating a convex hull goes from taking hundreds of hours to just seconds.
Other per-title encoding solutions have been introduced in the past year. They also attempt to circumvent the huge computational and time cost; however, they do this making certain trade-offs:
- They utilize CRF which means redundant encodes are still necessary. Additionally, analyzing CRF is not as accurate as measuring the encodes with a perceptual quality metric.
- They use fixed resolutions and vary the bitrates. This leads to unevenly spaced jumps in the bitrate ladder and wasted or inefficient bandwidth usage for the end-user.
Our deep learning approach allows us to bypass CRF encodes altogether, and gives us the accuracy of Netflix’s methodology while maintaining our speed requirements for just-in-time encoding. This means higher quality video for our customers at no additional cost.
Results
Our initial results have been been very exciting. Within an initial evaluation set of 44 videos representing a diverse mix of content, 86% of them showed improvements in quality as measured by VMAF. Certain clips showed differences as large as 12 VMAF points, as shown below:

You can view more results in our initial blogpost.
So why is this remarkable?
This is free video quality. Using this approach, we can stream higher resolutions at lower bandwidths and at zero additional cost to our end users. And it's only going to get better.
As our training set grows over time, we expect the accuracy of our model to further improve. Additionally, our deep-learning based approach allows us to transition from per-title encoding to per-shot encoding with relative ease since the network does not need to know the difference between predicting a convex hull for a full video vs for a single scene.
In many ways, this approach is better optimized for per-shot based encoding since we can train on a cleaner shot-based dataset, and the additional cost of outputting multiple convex hulls per video is virtually zero.
Lastly, a big advantage to our methodology is that the model can be re-trained on specific datasets based on the type of content provided. So when you upload videos to Mux, our system will learn based on your content and will provide increasingly better bitrate ladders tailored to your videos.
Have questions or comments? Tweet @MuxHQ.
Thanks for reading and we look forward to sharing future updates as we continue to improve our methodology!