
A common motivation for running a SaaS product in the cloud is to take advantage of elastic infrastructure. Many applications readily scale up and down in response to changing load; unfortunately, databases are not typically among them.
As usage of the Mux Data product has grown dramatically, processing billions of additional views each year, we’ve found ourselves operating increasingly larger databases to handle peak anticipated load. This has at times has proven both costly and difficult to scale.
In this post, we will examine a major improvement made to the Mux Data backend architecture, which involved moving from a shared, distributed Riak key-value (KV) store to the BadgerDB embedded KV store. This change enabled us to lower operational costs, boost scalability, and reduce latency in our data processing pipeline.
State of the world with Riak
There’s one Mux-specific concept here, and that is the notion of a video view; we’ll say view for short throughout this post. A view is one attempt to view a single video by one client device. Mux Data tracks each view through a series of event beacons sent by the client. The longer the view, the more event beacons get sent.
Riak might not enter the conversation much in 2023, but in 2016, it was considered one of most popular open-source highly available distributed KV stores. Mux Data has relied on Riak to meet two needs:
- A temporary cache for the details of a finished view, in case the view is resumed within the next 6 hours. Finalized video views are stored in a columnar database (see this post about when we started using Clickhouse) that’s ill suited for row-level access. A KV store could make the resumption of views faster and cheaper than querying the columnar-store database. This access pattern happens often (more than 20,000 times per second).
- A temporary cache for a partition of the views when processing moves between nodes. In our case, these are views hashed to a Kafka topic partition. Any time a Kafka consumer-group rebalance occurs and processing of a partition needs to move to another node, the state of inflight views associated with the partition must be moved too. This happens relatively infrequently (fewer than 10,000 times per day).
Riak served us well for many years, but times have changed. For one thing, Riak is no longer maintained by its creators at Basho. Riak served us well in 2016 compared with alternative distributed KV stores like Redis, which was challenging to deploy in a highly available, fault-tolerant configuration. But in the current environment, Riak is no longer the most natural fit.
Operational challenges with Riak
Riak became increasingly difficult to operate as Mux Data usage grew, compounded by a growing number of live video events. Unlike on-demand video consumption, live events have fundamentally different viewership patterns, which put stress on the KV store in ways that we hadn’t dealt with before:
- Large surge in viewership at the start of the event
- Many views being stopped and resumed during live event breaks
- Large surge in finished views at the end of the event
This viewership pattern contributed to the following operational challenges we had to overcome.
Scalability
Riak clusters can be elastic, allowing for more or fewer nodes to participate in the cluster. However, managing the number of Riak nodes was a very manual process. We deployed Riak as a Kubernetes statefulset with persistent volume claims (PVCs). The addition or removal of Riak nodes would require managing PVC volumes and redistributing stored state throughout the cluster. This is fine as an occasional activity, but it’s not well suited for autoscaling in response to daily usage patterns.
As a result, we ran Riak provisioned for the peak anticipated scale. This left us unable to take advantage of the elasticity of cloud computing resources with regards to running Riak. It also led to poor utilization of Riak’s compute and storage resources.
Cost
Static scaling naturally leads to cost inefficiency. Riak quickly became our second largest cost in the Mux Data stacks used to monitor large live events.
Stream processing latency
Processing latency was another concern, as Riak often became a write-throughput bottleneck when viewers left a stream en masse: think of a sports halftime break, when thousands or millions of viewers switch to another stream. This effect can lead to millions of video views being finalized within seconds, resulting in what’s effectively an internal denial of service from a large number of synchronous, blocking writes to Riak.
Degraded Riak write performance could cause stream-processing lag, possibly leading to delayed data in our Mux Data Monitoring dashboard, where we target less than 30s of glass-to-glass latency. Minimizing stream-processing lag is one of our main goals; it became difficult for us to feel confident in our ability to reach those goals using a statically scaled Riak cluster.
“Shared Nothing” architecture
As we began investigating alternatives for Riak in the Mux Data system architecture, one question we asked ourselves was whether a distributed KV store was even necessary for this particular problem.
The Mux Data event processors read video view beacons from Kafka topic partitions, where beacons are keyed to a specific partition based on the video-view-id, guaranteeing that the beacons for a view will always be on the same partition.
This means the cache could be scoped to a single Kafka topic partition.
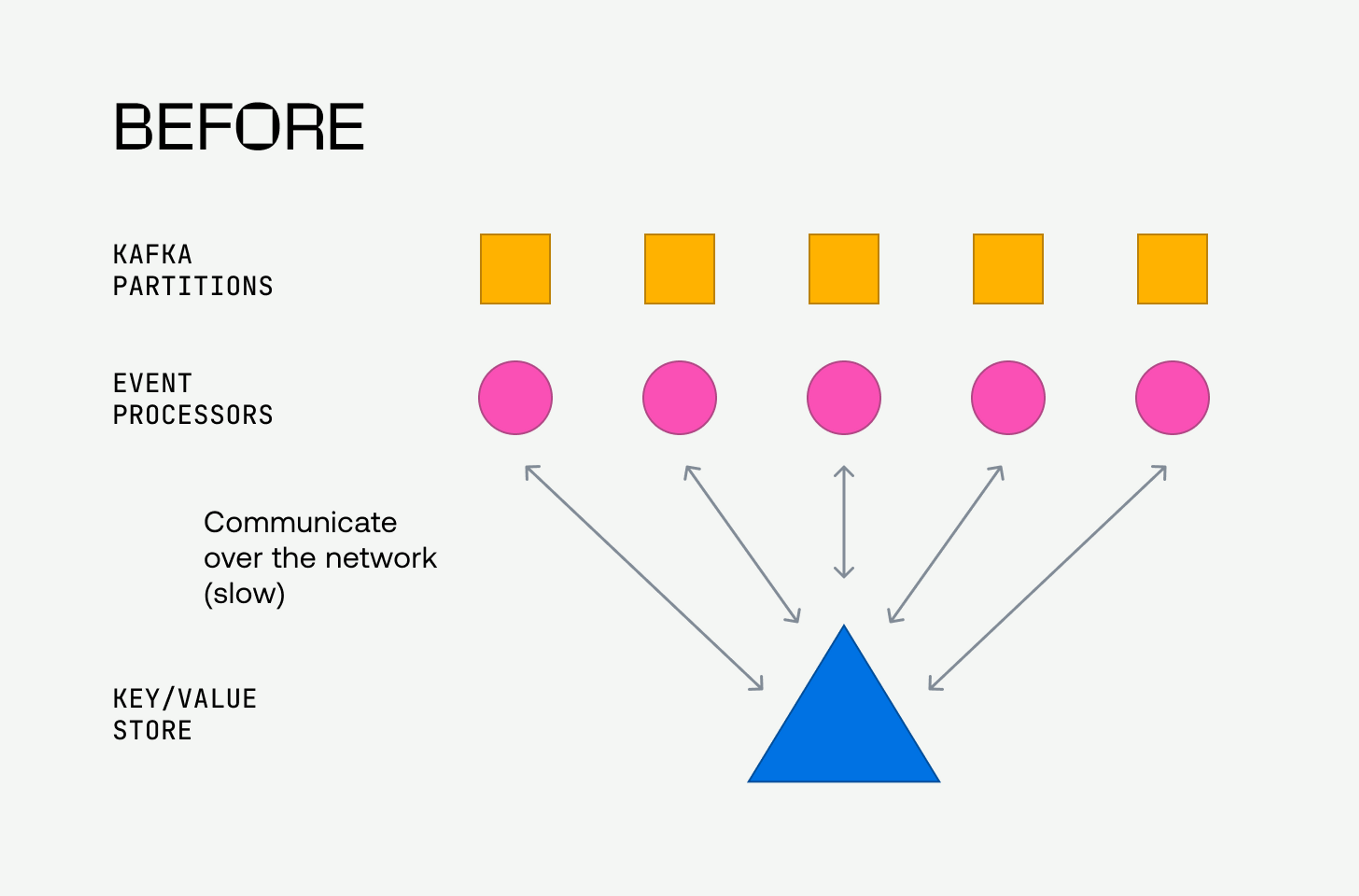
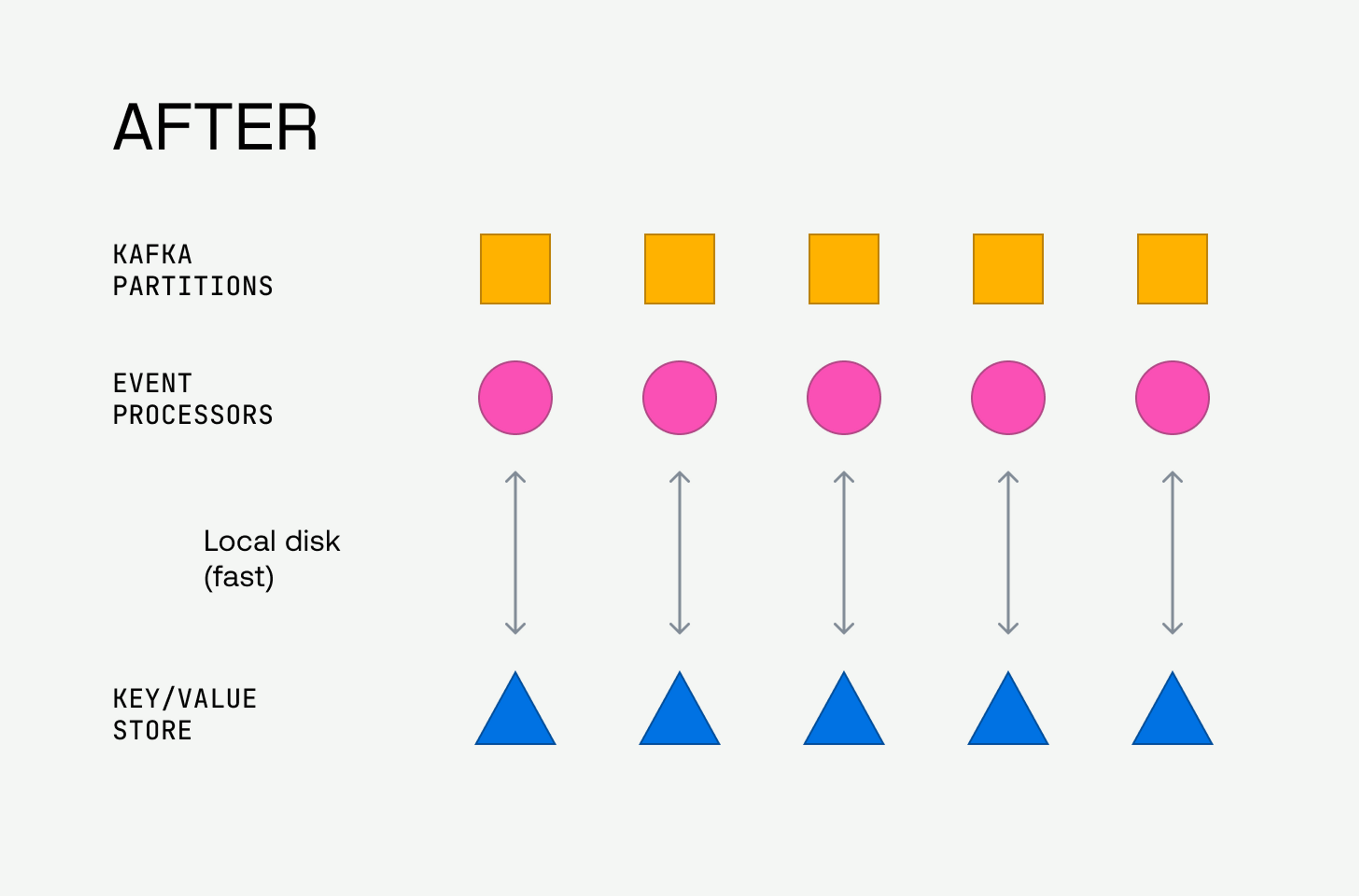
So, rather than running a networked, distributed KV store (Riak, Redis, etc.), we could instead have the event processors manage many independent partition-scoped embedded KV stores on local disk. We could use a networked storage system like S3 to stage the embedded KV store files on the infrequent occurrence of a Kafka topic partition reassignment, such as during pod termination on an upgrade or scale-up/scale-down.
This approach allows us to optimize for the performance of the frequently occurring activity (see “a temporary cache for the details of a finished video view” above), which is the most performance sensitive.
We could address the infrequently occurring activity (see “a temporary cache for a partition of the views when processing moves between nodes” above) through new code. This would incur some additional application complexity, but it could yield significantly better performance for the hot code paths, unlock significantly greater scale, and reduce operational costs. This was a development cost worth paying.
Our use of a networked KV store was an optimization we made in 2016 in the interest of developer efficiency. Teams should periodically reevaluate which problems they’re optimizing for (i.e., cost and scaling efficiency vs. developer efficiency). Priorities change!
Scoping the cache to a Kafka topic partition follows the “Shared Nothing” architecture described in Martin Kleppmann’s book “Designing Data Intensive Applications”:
Normally, partitions are defined in such a way that each piece of data (each record, row, or document) belongs to exactly one partition. … In effect, each partition is a small database of its own, although the database may support operations that touch multiple partitions at the same time.
The main reason for wanting to partition data is scalability. Different partitions can be placed on different nodes in a shared-nothing cluster. Thus, a large dataset can be distributed across many disks, and the query load can be distributed across many processors.
We leveraged the keyed, partitioned nature of the data in Kafka to scope each cache to a single Kafka topic partition, leading to a cache architecture following the Shared Nothing pattern.
A Shared Nothing architecture meant we could potentially scale beacon processing almost limitlessly without needing to scale the KV store; the beacon processing and KV store systems would become one and the same.
The Mux Data event processors autoscale based on CPU and memory usage, closely tracking the number of active views being monitored. As the number of inflight views changes throughout the day, so does the number of processor pods, and the number of partitions consumed by each.
When assignment of a partition moves to a different event processor, the previous partition leaseholder flushes its state to the on-disk KV store cache, closes the cache files, and transfers them to S3. The new partition consumer subsequently downloads the cache files from S3, loads the inflight view state, and resumes reading from the partition.
This state hand-off is more complicated than if we were to use a distributed KV store, but the performance and cost improvements have made it worthwhile in the end. Not gonna lie, we had to tackle a number of bugs (some lurking for years!) to make this work. The time-sensitive nature of this hand-off made it tricky.
The solution
Integrating BadgerDB
The Mux Data backend is largely written in Go, so our preference was for a native Go-embedded KV store. There are several, which is both good and bad news.
Our first iteration used the BBoltDB project, an actively maintained fork of boltd managed by the etcd team. As we came to find out, boltdb is well suited for infrequent writes and frequent reads. Our use case includes equal parts writes and reads. We saw poor write performance from boltdb and had few settings that could be tuned, which led to us evaluating alternatives.
Our second implementation attempt used the BadgerDB KV store, which the Mux Video product has used for several years as an ephemeral cache. Being able to leverage a single technology in multiple places was a major win.
Reasons for choosing BadgerDB included:
- High performance writes and reads
- Control over frequency of on-disk cache garbage collection
- Granular control over data layout on disk with target segment sizes
- Compression
Integrating BadgerDB into the Mux Data processors was straightforward, largely thanks to a simple Store interface used by all of our cache implementations, embedded or remote:
type Store interface {
Set(context.Context, []*CacheEntry) error
Get(context.Context, string) (*CacheResult, error)
Close(context.Context) error
MarkCacheActive(context.Context)
}The Set and Get functions are self-explanatory.
type CacheResult struct {
Exists bool
Value []byte
}
type CacheEntry struct {
Key string
Value []byte
}
func (b *badgerDBStore) Set(ctx context.Context, entries []*CacheEntry) error {
wb := b.db.NewWriteBatch()
defer wb.Cancel()
for _, v := range entries {
entry := badger.NewEntry([]byte(v.Key), v.Value).WithTTL(b.SweepTTL)
if err := wb.SetEntry(entry); err != nil {
ctx.Log().Errorf("Error writing key and value to BadgerDB as part of a batch: %v", err)
return err
}
}
err := wb.Flush()
if err != nil {
ctx.Log().Errorf("Error flushing write batch to BadgerDB: %v", err)
return err
}
return nil
}
func (b *badgerDBStore) Get(ctx context.Context, key string) (*CacheResult, error) {
var val []byte
if err := b.db.View(func(tx *badger.Txn) error {
dbVal, err := tx.Get([]byte(key))
if err != nil {
return err
}
return dbVal.Value(func(v []byte) error {
val = v
return nil
})
}); err != nil && err != badger.ErrKeyNotFound {
ctx.Log().Errorf("Error performing Get to BadgerDB: %v", err)
return nil, err
}
if val != nil {
return &CacheResult{true, val}, nil
}
return &CacheResult{false, []byte{}}, nil
}The Close function performs any finalization of the cache, including writing the cache to S3 storage, which happens only if the cache was marked as active (in use) via a call to MarkCacheActive.
Disk storage
There’s also the issue of data storage. Our Riak cluster used AWS Elastic Block Store (EBS) volumes for storage. Shifting cache storage to the event processor pods in our Kubernetes cluster required us to add support for local ephemeral storage on the associated Kubernetes nodes.
Mux Data runs in AWS and has largely used the m5 family of EC2 instance types. We moved from m5 to m5d instances to gain access to ephemeral node-local storage that could be used for temporary storage of the BadgerDB KV cache files. This storage makes use of locally attached SSDs that offer high throughput without the network variability that comes from EBS.
The use of local attached storage meant we no longer had contention on a shared networked resource (the network, Riak, or EBS), which is especially important when responding to viewership spikes during live events.
Results
Since migrating our inflight KV store from Riak to BadgerDB, we’ve seen significantly lower latency from the processors, even at levels of scale that were 4x what we handled with Riak. Elimination of the network request to Riak for each KV set and get operation has made handling view stop-and-start behavior a non-issue.
We’ve also been able to handle significantly larger-scale events without any scaling concerns from the event processors. By removing external dependencies for hot code paths, we have been able to perform more predictably and with lower latency.
Finally, elimination of the statically scaled Riak cluster and its replacement of an embedded KV store in the autoscaled event processors has reduced operational costs and complexity.
Conclusion
Our journey in the migration from Riak to BadgerDB has been both challenging and eye-opening. We’ve made significant investments in Mux Data’s scalability and performance, and we’re proud to share our insights with the broader engineering community.
Our experiences have shown us that while distributed KV stores have their place in software architectures, they can prove difficult to scale at certain levels. We have found that embedded KV stores and a “Shared Nothing” architecture can be an effective solution to this problem. However, it’s crucial to consider the problems you’re optimizing for and their frequency.
Scaling an application to these levels can be challenging, but it’s also evidence that you’ve built something people want. At Mux, we believe in continuous learning and improvement. This project has not only allowed us to grow, but also reinforced our commitment to delivering high-quality, efficient, and performant solutions.
We're excited about the future of Mux Data and look forward to sharing more of our journey with you. Thank you for joining us on this adventure, and we invite you to stay tuned for more updates on our progress and learnings.


