
Running in the public cloud you often have to rely on your cloud provider’s managed services to load-balance ingress traffic. But is it always a good solution for non-HTTP connections, in particular long-lived TCP flows such as RTMP? While hunting for a pesky live streaming bug, we discovered that virtual load balancers don’t always simulate their physical counterparts the way you might expect.
Following the White Rabbit
Mux's Live Streaming API provides an RTMP endpoint which receives a video/audio stream from encoder software or hardware (e.g OBS.Live, Wirecast, FFmpeg, or 3rd-party cloud encoders). The ingested stream is then transcoded/transmuxed and broadcast to thousands of viewers via our live HLS playback stack. We allow up to 12 hours of uninterrupted broadcast for each live stream.
In our original design, we exposed our RTMP ingest workers to the outside world via Google Cloud’s Network Load Balancer to simplify our worker deployment and DNS management. In this setup we expose only a single public VIP (virtual IP) shared between all RTMP workers - which we can take out of service gracefully during an upgrade, scaledown, or other maintenance:
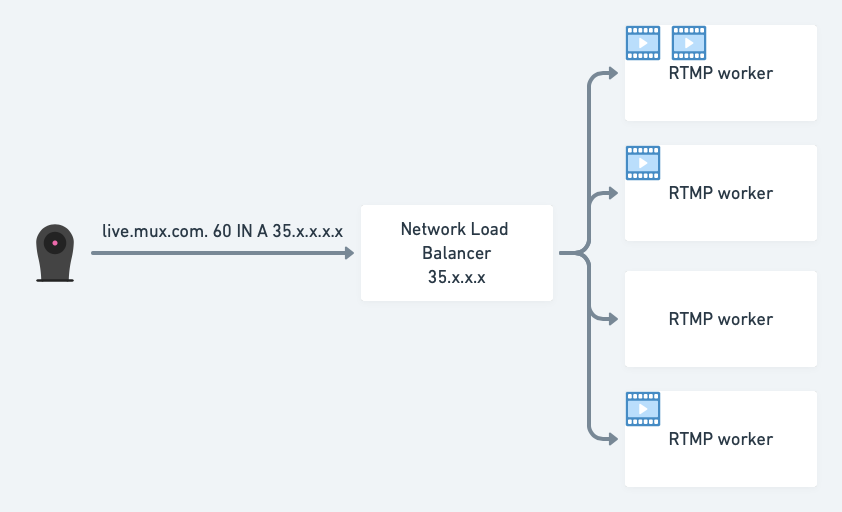
The workers have finite computing capacity and therefore can only perform a limited number of transcodes simultaneously before they start lagging behind real time - only 2-3 streams at the time. In order to limit the number of incoming new connections from the cloud load-balancer, our ingest application would declare itself as “unhealthy” via the built-in Network Load Balancer’s HTTP health check whenever a worker had accepted 2 active streams. If both active streams land at once, and continue for the maximum allowed time, the worker could remain “unhealthy” for those 12 hours.
After at least one of the streams is over and the number of active streams falls below the threshold, the worker will re-declare itself “healthy” to the Network Load Balancer that periodically checks in on its health. At this point the worker is ready to accept new connections. We used this same health-check workflow to drain the node out of the load-balanced group gracefully, and let existing streams run to completion. We relied on this workflow to perform software upgrades, node pool scaledowns, and other maintenance.
At the beginning of the COVID pandemic lockdowns, we saw an increase in our live streaming usage; we also saw an increase in customer reports about RTMP streams experiencing occasional disconnects. On our end, the reported streams were disconnecting when the 5-second idle timeout ran out after the client’s encoder had seemingly hung up.
We collected more traces for the affected streams, and found that they indeed were timing out. According to our RTMP server logs:
[error] 8#0: *30769 live: drop idle publisher, client: 52.x.x.x, server: 0.0.0.0:1935
When we looked closer, we noticed an interesting pattern: an RTMP worker’s streams had a much higher likelihood of dropping if it had reached the maximum number of connections. At first we suspected that certain streams could overload our machines even with just two streams running, but after digging through all of the performance-related metrics and traces we saw no evidence of this. To make things harder, the bug didn’t seem to be consistently reproducible, even when machines reached maximum stream capacity. Sometimes streams would run the full 12 hours while others would drop after only a few minutes.
We started collecting packet captures to see if anything out-of-ordinary was happening at the protocol level. Right away, we noticed something interesting: our test client would receive a TCP RST (connection reset) 5 seconds before the stream would go idle on the server side. Remember that 5-second idle timeout we mentioned before?
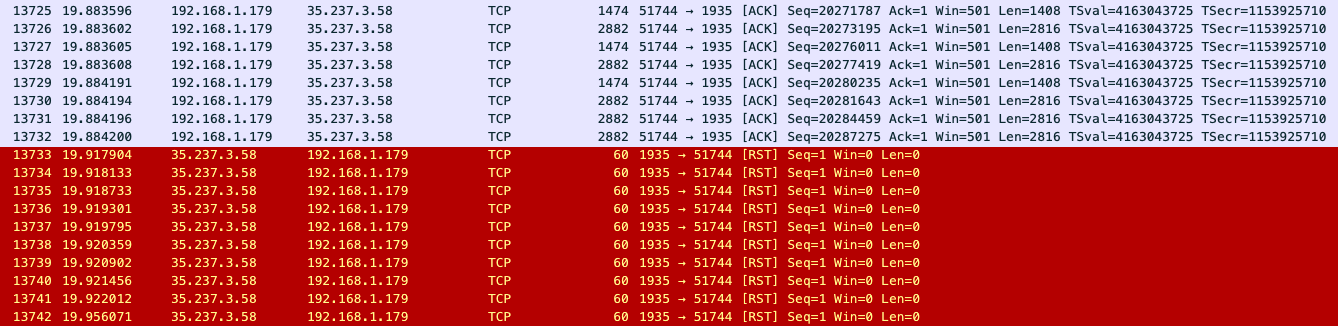
Packet capture on the corresponding server showed no TCP RST packets being sent. What we did find was that, at some point, the incoming packets stopped flowing.
Strongly suspecting shenanigans at the load-balancing layer, we went with a hunch. We deployed a tcpdump background process configured with a '(tcp[tcpflags] & (tcp-rst) != 0) and (port 1935)' filter to every worker in our fleet, and lo and behold:
April 5th 2020, 23:49:44.003 [error] 8#0: *30769 live: drop idle publisher, client: 52.x.x.x:33900, server: 0.0.0.0:1935 ← RTMP worker serving dropped stream
April 5th 2020, 23:49:38.887 35.237.3.58.1935 > 52.x.x.x.33900: Flags [R], cksum 0x4c26 (correct), seq 3716194182, win 0, length 0 ← totally unrelated worker
Note that the second record is time-stamped almost exactly 5 seconds before we see an idle timeout occur on the RTMP worker serving the stream. The packets are being forwarded to the wrong host! That host doesn’t have any knowledge of the RTMP (TCP) stream in question so it just sends a “go away” reply (TCP RST) to the client, which promptly hangs up - disconnecting the live stream's encoder and leaving viewers to rebuffer while they wait for more video to arrive.
The obvious next question is, why is this happening? It can't be normal behavior for Network Load Balancer to occasionally send a packet to a random backend destination. What could be going wrong? You might have already guessed that the problem is with how the Network Load Balancer uses health checking to see whether a service is at capacity. To understand why this is happening, we first have to look at how the Network Load Balancer actually works.
The Desert of the Real (packets)
Google Cloud documentation shows that the Network Load Balancer implementation uses Maglev under the hood. Maglev is a software-based load-balancer based on proprietary technology developed by Google. It can be classified as “L4 packet forwarder”... which means that it’s not actually terminating TCP sessions. Instead, it inspects TCP/IP headers to load-balance TCP flows consistently across backends. In order for this to work, all of the packets for a flow have to go to the same backend once the connection has been established. Facebook uses a very similar design in their Katran project. GitHub has open-sourced their own variant of this design in their GLB project.
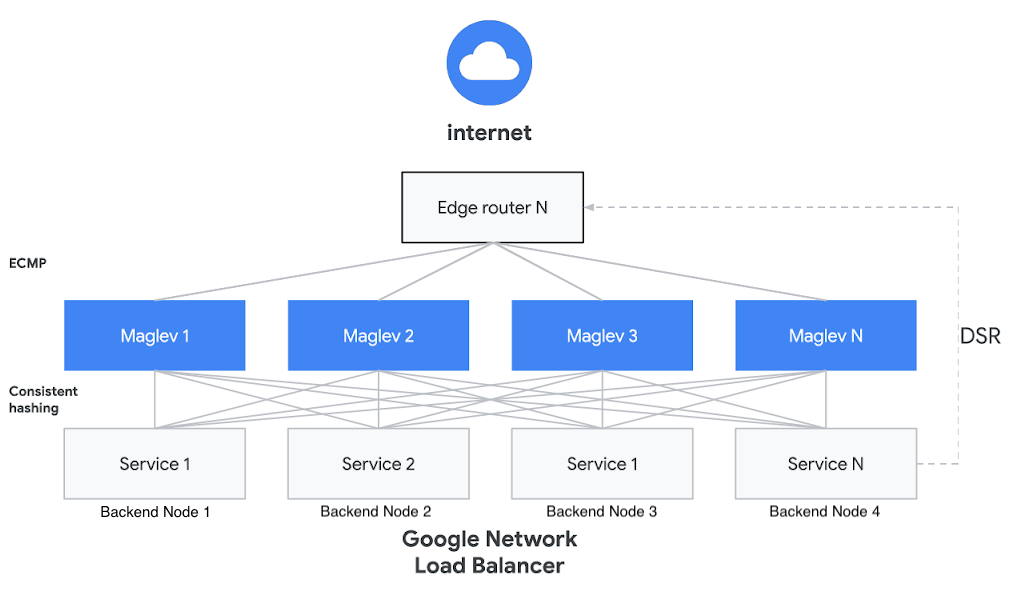
The underlying design involves L4LB nodes (Maglev, Katran, GLB) that each establish a BGP session to an upstream Edge router, enabling all of them to advertise the same VIPs. This results in the Edge router fanning out all incoming traffic with a destination IP matching the shared VIP across multiple L4LB nodes using ECMP routing. A Service backed by a VIP can have one or more replicas distributed across distinct backend nodes (in the above diagram, Service 1 runs on Backend Nodes 1 and 3). On each of the L4LB nodes, packet forwarding software uses a clever hashing scheme to consistently map individual TCP flows to the set of backend nodes using 5-tuple of values from packets’ TCP/IP headers (source IP, source port, destination IP, destination port, protocol).
For example, when you have a TCP session established between a client 1.1.1.1:31415 and a VIP 1.1.1.2:1935 (Service 1), all of the packets for this flow will be directed to the same backend node (e.g., Backend Node 1), regardless of which L4LB node (Maglev 1, 2… N) receives the packet. The consistent hashing scheme is the key property of this load-balancing setup; this allows the Maglev forwarding plane and backend nodes to scale independently of each other and, in theory, with zero downtime.
However, since Maglev relies on consistent hashing with small look-aside connection tracking tables to perform distributed cache coordination, there are still edge cases that lead to TCP packets being forwarded to the wrong backend. For example, when a backend fails a health check (i.e. when the backend intentionally declares itself unhealthy to be taken out of service), then the L4LB will rely on its connection tracking table to load-balance the remaining connections to that backend. However, if a set of L4LB nodes also changes, or the connection cache is thrashed by something like a SYN flood, Maglev may not consider the draining backend node in its packet assignment process, and as a result will forward the packet to an unsuspecting backend node.
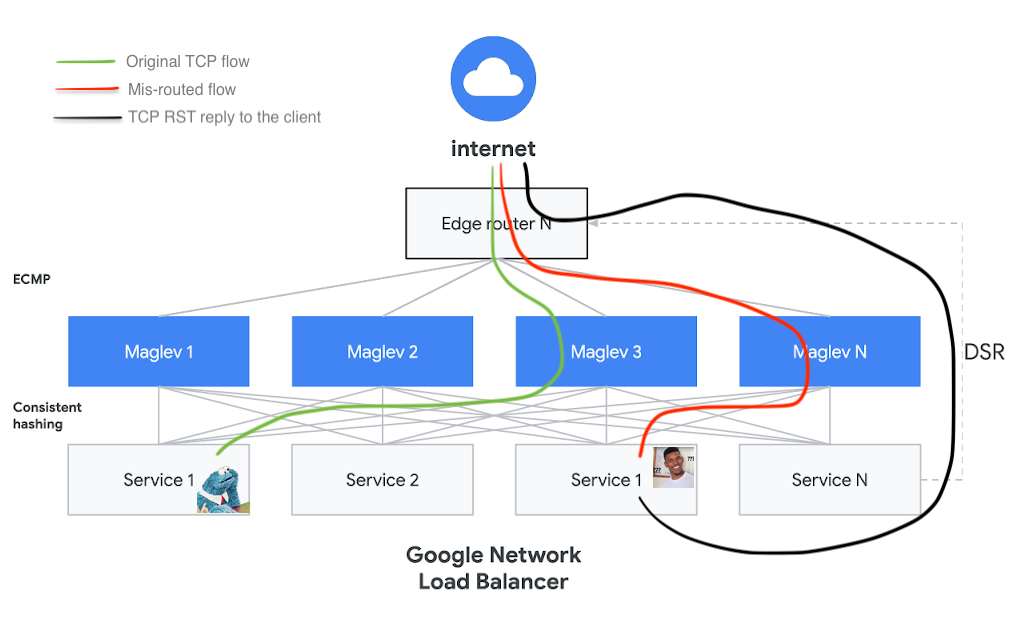
It’s easy to see how with a multi-hour TCP connection drain this design can prove pretty unstable, and this is exactly what we experienced in production. Unless you have full control of your L4LB plane, it’s pretty much impossible for this setup to reliably maintain TCP flows during backend drains. This also explains why sometimes connections would survive (i.e., when nothing at the L4LB layer scaled or otherwise changed) and sometimes they would drop fairly quickly. For regular HTTP-based web applications this shouldn’t be much of a problem because most connections don’t last for very long anyway (although it makes us wonder if this affects HTTP/2 or TURN/TCP flows similarly).
Enter Envoy
It became apparent that we couldn’t make our existing design work using managed cloud infrastructure, so we needed a new design. Here are some of the requirements:
- The ingest load has to balance between RTMP worker nodes so they don’t become overloaded.
- RTMP workers must be easy to take out of service (for maintenance, upgrades, etc.) with no customer impact.
- The solution has to work with “standard” RTMP over TCP. We don’t control our customers’ encoders’ TCP stacks. No eBPF, Wireguard magic, or secret spells allowed.
- It must run in a public cloud. Rebuilding our stack on bare-metal hosting would be impossible under our time constraints.
The obvious approach was to integrate our existing health checking system with a traditional L4 load-balancing setup. After considering NginX, HAProxy, and Envoy as potential solutions, we chose Envoy for its programmability and relative ease of integration with our existing stack.
In this design, a pool of Envoy proxies, each with a distinct public IP, terminates the TCP connection for an RTMP stream and reverse-proxies all packets on another TCP connection to an RTMP worker. Envoy proxies are in turn load-balanced and drained using DNS round-robin and blue/green setup respectively:
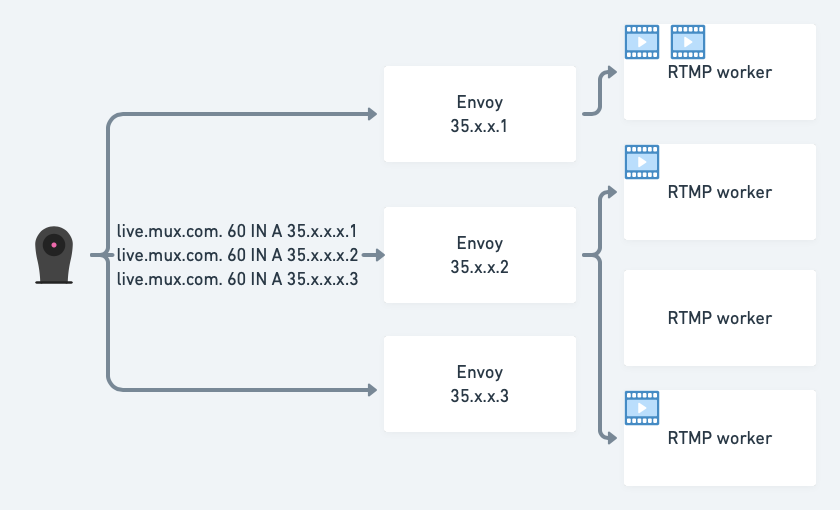
Envoy is typically advertised as an L7 proxy but at its core it’s actually a L3/L4 network proxy, so it fits our use-case perfectly. Also, it natively supports gRPC/Protobuf in the data and control planes. We had already widely adopted gRPC/Protobuf across our stack, so we were able to quickly integrate it for this use case. Envoy’s entire configuration is defined in Protocol Buffers.
Envoy can be configured fully statically via a config file, dynamically, or with a hybrid static/dynamic approach. Our RTMP Envoy deployment uses a hybrid method: the static portion of the configuration is shipped as a Kubernetes ConfigMap, and the dynamic portion is continuously delivered using Envoy’s xDS (Dynamic Service Discovery) gRPC service. Let's look at the static portion first:
node:
cluster: rtmp-edge
static_resources:
listeners:
- name: rtmp
address:
socket_address:
address: 0.0.0.0
port_value: 1935
filter_chains:
- filters:
- name: envoy.tcp_proxy
typed_config:
'@type': type.googleapis.com/envoy.config.filter.network.tcp_proxy.v2.TcpProxy
stat_prefix: ingress_tcp
cluster: rtmp-workers
In the above section we set up a TCP listener on port 1935 and chain it to the rtmp-workers cluster for actual load-balancing:
clusters:
- name: rtmp-workers
type: EDS
eds_cluster_config:
eds_config:
api_config_source:
api_type: GRPC
grpc_services:
- envoy_grpc:
cluster_name: xds_cluster
connect_timeout: 0.250s
- name: xds_cluster
type: STRICT_DNS
connect_timeout: 10s
load_assignment:
cluster_name: xds_cluster
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: [RTMP Controller DNS]
port_value: 31415
http2_protocol_options: {}The rtmp-workers cluster is configured to load-balance across dynamically configured endpoints (EDS stands for Endpoint Discovery Service) delivered by another cluster within this configuration - xds_cluster. xDS cluster in turn connects to our Endpoint Discovery service that tracks available RTMP worker endpoints using the Kubernetes API:
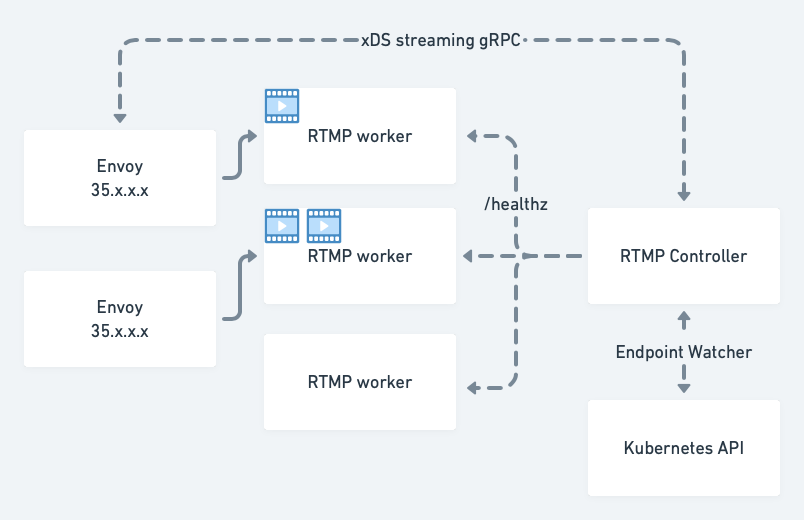
The RTMP controller component is responsible for tracking in-service RTMP worker pods, continuously health checking them and re-configuring all connected RTMP Envoys. Envoy receives LoadAssignment messages in a configuration snapshot via a streaming gRPC call which (rendered in YAML) looks like this:
- "@type": type.googleapis.com/envoy.api.v2.ClusterLoadAssignment
cluster_name: rtmp-workers
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 10.x.x.1
port_value: 1935
- endpoint:
address:
socket_address:
address: 10.x.x.2
port_value: 1935
- endpoint:
address:
socket_address:
address: 10.x.x.3
port_value: 1935To upgrade Envoy nodes themselves, we fully roll the whole pool using a blue-green deployment strategy. For example, we replace blue Envoy IPs in our multi-value DNS record with green ones, and let the blue pool drain for several days. We’ve found that some DNS resolvers / applications can cache replies for a long time even when we have set a relatively low TTL. We only have to perform this procedure when updating the static portion of Envoy’s configuration, the Envoy container itself, or the underlying node.
Here are some pros and cons we’ve found with our new design:
Pros:
- Most importantly: no more connection drops when draining RTMP workers!
- We control more of our backend stack - we decide when it’s time for maintenance, not Google.
- Opens the door to some new features such as TLS certificates with wildcard names, unlimited number of SANs, etc. (although we could’ve done this by just running Envoys or other reverse proxies behind Google's Network Load Balancer)
Cons:
- We have to manage more of our backend stack - more operational overhead on the team.
- More machines with public IPs in service equals higher costs.
- DNS load-balancing of the edges themselves requires a high amount of overprovisioning due to node bandwidth constraints. Most clouds allocate bandwidth based on CPU count / instance size - which means we pay for lots of cores and memory even when they're sitting idle.
This architecture has been running in production since July of 2020 and we’ve observed significantly improved connection reliability. Overall, we’re happy with this design but our new Envoy-based RTMP edges do impose added complexity and operational overhead.


